뉴스젤리 리포트
Korea’s public data openness index ranked first, quality?
Have you ever used public data? The Government strives to actively open up public data by the Act on Providing and Utilizing Public Data. Through data liberalization, the government aims to strengthen transparency and accountability by allowing citizens to understand what the government is doing. It is not just to improve government performance, but also to create innovative services that help people live their lives using open data and improve personal decision-making.
In order to achieve this goal, it is important not only for government to open data, but also for public interest and participation. Will the citizens actively use the amount of data they have opened? We need to create an environment where citizens can find and use data easily and conveniently. So it’s important to create a public-friendly data experience with high-quality data.
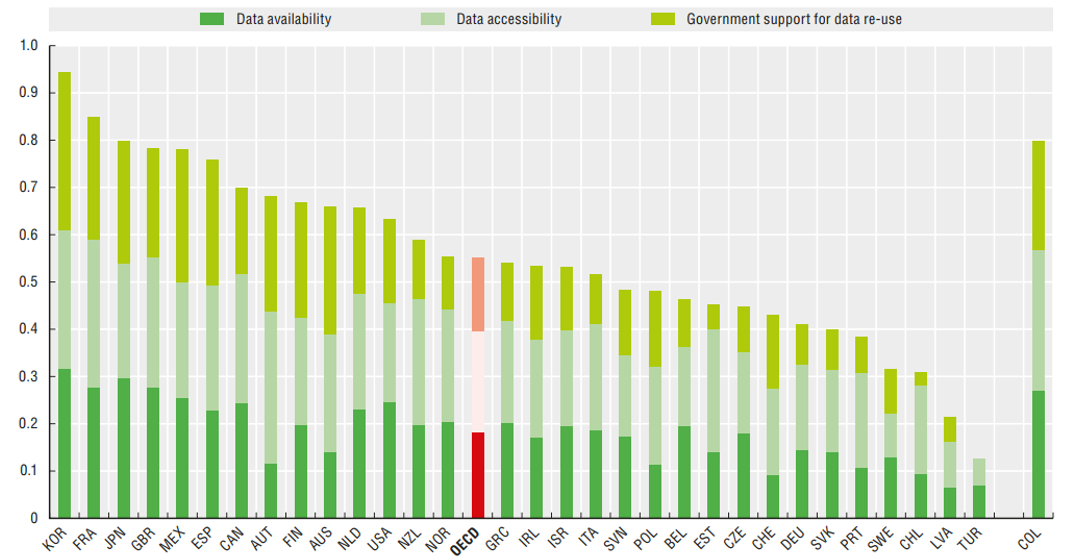 OECD Survey on open Government Data )” width=”1077″ height=”559″> OECD Public Data Open Assessment Status. The indicator on the left-hand bar graph (KOR) is the highest among the OECD countries (Source: OECD Survey on open Government Data ).
OECD Survey on open Government Data )” width=”1077″ height=”559″> OECD Public Data Open Assessment Status. The indicator on the left-hand bar graph (KOR) is the highest among the OECD countries (Source: OECD Survey on open Government Data ).
Preparing for Public Data Quality Assessment
As of 2017, Korea ranked second in the OECD public data openness evaluation. [1] In short, the data openness of Korea is excellent. But as I said, more important is the quality of the data. The easier it is to use and the more quality data that has the potential to utilize, the greater the ripple effect of the openness of public data. Therefore, it is necessary to check the current situation and complement the quality.
To this end, News Jelly, a company specializing in data visualization solutions , investigated the quality of public data opened by domestic metropolitan governments by applying the Open Index Barometer (ODB) Performance Index Survey Methodology [2] . The Open Data Barometer is the result of the World Wide Web Foundation’s annual international index of public data openings divided by readiness index, performance index, and impact index, each of which is rated as a 100-point scale .
[1] Korea, OECD Public Data Openness Assessment Report for 2 consecutive times (Yonhap News, July 17, 2017)
[2] Open Data Barometer 4th edition Research Handbook – v1.0 (2016.6)
For each index, the ‘Preparedness Index’ is a preliminary strategy for preparing to open up public data, and a survey of experts, education, law, and activities from government, business, and citizens.
다음으로 ‘실행 지수’는 한 국가가 실제로 개방할만한 데이터를 지도, 기관 통계, 기관 예산, 기관 지출, 기업 명부, 법률, 대중교통 시간표, 의료 성과, 교육 성과, 범죄 통계, 환경 데이터, 공공계약 데이터, 무역 데이터, 선거 결과, 토지 소유 데이터의 15개 종류로 나누어 각각 평가를 시행합니다. 각 종류를 Table 1에서 제시된 10개 항목으로 조사한 다음 각 항목에 특정 가중치를 적용해 100점 만점으로 환산하는 방식으로 개별 데이터 종류를 평가합니다. 그리고 개별 데이터 점수 결과의 평균값으로 국가의 데이터 실행 총점을 매깁니다.
마지막으로 ‘영향 지수’는 정치, 사회, 경제의 3분야에서 공공데이터가 미친 영향을 전문가 설문조사로 평가합니다.
다만, 뉴스젤리는 이번에 시행한 공공데이터 품질 평가에서 ODB의 실행 지수만을 이용하여 조사했습니다. 이유는 크게 3가지입니다. 먼저 직접적으로 공공데이터 자체를 다루는 지표가 실행 지수 뿐입니다. 준비 지수는 데이터 개방을 위한 사전 작업을 평가하는 것이고, 영향 지수는 데이터 개방의 파급 효과를 측정하기에 공공데이터의 질을 직접 다루지는 않습니다. 반면 실행 지수는 사용자 친화성, 활용 가능성의 관점에서 직접적으로 데이터 품질을 다루는 지표라고 할 수 있습니다.
☞ 뉴스젤리 공공데이터 품질평가에 활용된 실행지수 조사결과 자세히 보기
또한, 준비 지수와 영향 지수는 단일 지자체를 위한 지표로 가공하기가 어렵다는 것도 하나의 이유입니다. 준비 지수는 데이터 개방 인프라에 관한 것이기에 단일 지자체에 국한되지 않고 정부나 시민의 행보가 지수에 큰 영향을 미칩니다. 또 개인이 특정 지자체의 데이터만 사용하는 것은 아니기 때문에 영향 지수에서도 단일 지자체의 영향력만 분리해서 평가하기가 사실상 불가능합니다. 반면 실행 지수는 데이터 개방 실태만을 평가하는 것이므로 자치단체 각각의 데이터를 평가하는 데 적합합니다.
마지막으로 실행지수가 상대적으로 정량화 가능성이 높습니다. 준비지수나 영향 지수는 점수를 산정하기 위해서 언론 등을 보고 복잡한 판단 과정을 거쳐야 하는 반면 실행지수는 앞서 설명한 15개의 데이터 종류까지 정해진 가운데 각 종류별로 세부적인 평가 대상 데이터를 잘 정의한다면 데이터에 포함된 요소의 존재 유무에 따라 이분법적으로 비교적 단순한 평가를 할 수 있습니다.
이 외에도 각 광역자치단체를 일관되게 평가하기 위해서는 평가 대상인 12가지 종류의 데이터에 대해 보다 세부적인 정의가 필요합니다. 이번 조사에서는 평가할 데이터의 구체적인 정의를 다음과 같이 내렸습니다.

각 광역자치단체의 일관적인 평가를 위해, 평가 대상인 데이터를 세부적으로 정의하였다. 총 12개의 항목 중 주요 데이터 항목 정의만을 선별해보았다.
※ 만약 특정 종류 데이터가 예를 들어 데이터 포털, 통계 포털, 청사 홈페이지 중 복수의 소스에 존재한다면 점수가 더 높은 것을 선택
※ 광역자치단체를 평가하기 위해 데이터 종류 중 중앙기관이 주로 관리하는 것으로 판단되는 무역 데이터, 선거 결과, 토지 소유 데이터는 이번 평가 대상에서 제외했습니다.
지자체별 공공데이터 품질 평가 점수 실태
“100점 만점에 전체 평균 31.6점, 하향치 겉돌아”

광역자치단체 공공데이터 품질 자체 평가 점수
이러한 전제를 바탕으로 최종 집계한 결과, 총 17개의 자치단체 중 서울시가 약 57점을 기록하며 가장 우수한 성적을 보였습니다. 이 외 대부분의 자치단체는 20점대 중반에서 30점대에 분포되어 있었습니다. 여기서 주목해야할 점은 본 평가지수의 총점이 100점 만점인 것을 감안하면 국내 자치단체들의 데이터 활용 정도는 전반적으로 높지 않다는 것입니다. 어째서 이런 결과가 나타난 것일까요?
※ 각 자치단체 공공데이터 포털, 중앙 공공데이터 포털 및 청사 홈페이지, 기관 산하 기타 하위 포털 (통계, 교통 정보 등)에 의거
※ 각 자치단체의 데이터 종류 별 자세한 점수와 구체적 산정 기준, 이유는 아래의 데이터 평가 문서에서 확인하실 수 있습니다.
지자체 공공데이터 품질평가에서의 주요 시사점
1. 여러 곳에 산재되어 있는 자치단체의 공공데이터

여러 곳에 산재되어 있는 자치단체의 공공데이터
광역자치단체 공공데이터 평가를 하면서 가장 눈에 띄는 것은 여러 종류의 데이터를 한 곳에서 찾기 힘들다는 점이었습니다. 위 사진들은 항목별로 데이터를 찾는 데 이용한 인천광역시 산하 사이트들입니다. 인천광역시의 경우 자체 데이터 포털이나 공공데이터포털이 평가 대상이 되는 데이터 전종류를 포괄하지 못했습니다. 그리고 두 포털 이외에 데이터를 제공하는 사이트가 5곳 이상으로 분산되어 있습니다. 이는 대부분의 광역자치단체에 해당하는 사항입니다. 또 같은 종류의 데이터라도 광역자치단체에 따라 데이터 분포 및 현황도 다른 것으로 나타났습니다. 따라서 종류별로 필요한 데이터를 찾기 위해서 이용자는 큰 혼란을 겪을 것으로 예상됩니다.
문제는 이처럼 각 종류별로 게시된 사이트가 다르다보니 형식이나 업데이트 주기 등의 여러 요소도 일관되지 않을 가능성이 크다는 것입니다. 또 같은 항목에 대해서도 자치단체끼리 다른 형태를 띠고 있는 경우가 많습니다. 그러다보니 사용자로서는 혼란이 커질 수 있고 필요한 각각의 데이터를 찾거나 활용하는 데 다소 많은 시간을 소요하게 됩니다.
또 미처 관련 사이트들을 다 탐색하지 못해 사용자에게 필요한 데이터가 실제로는 존재함에도 불구하고 이용하지 못하는 불상사가 일어날 가능성도 있습니다. 해당 사이트를 찾아도 필요한 특정 데이터를 찾는데는 데이터 포털에서의 검색을 통하는 것보다 시간이 걸리는 경우가 많습니다. 데이터 포털에 있는 정보들은 게시, 수정 시간이나 형식, 라이선스 표기 등이 비교적 잘 되어있기 때문입니다. 따라서 분산되어 있는 각종 데이터들을 단일 데이터 포털에 최대한 모으고 형식도 통일하는 작업이 시급하다고 판단됩니다.
2. 모든 시도가 공개하지 않은 기업 명부

모든 시·도가 공개하지 않은 기업 명부
위 사진은 공공데이터 포털에 존재하는 울산광역시 기업 명단 중 일부입니다. 마을기업 및 사회적 기업, 제조기업 등 대부분의 지자체가 일부 기업에 대한 명단은 공개한 상태였으나 모든 범위의 기업을 포괄하는 사례는 없었습니다. 평가 대상인 12가지 종류의 데이터 중 모든 시도가 0점을 맞은 데이터가 기업 명부 데이터였습니다.
3. 대부분의 도에서 일괄 구축되지 않은 버스 정보
대부분의 도에서 일괄 구축되지 않은 버스 정보
또 하나 확실한 경향성을 띠는 사항은 위의 사진들처럼 광역시들은 버스 정보 시스템을 구축하고 대부분 오픈 api 형식으로 버스 도착 정보까지 공개한다는 것입니다. 반면 도의 경우 경기도나 제주도 정도를 제외하고는 일부 시, 군만 버스 정보 시스템을 구축하는데 그쳤습니다.
이는 도 내의 일부 낙후된 지역까지 제대로된 인프라를 구축하기 어려우므로 버스 정보 시스템의 일괄 구축이 되지 않고 있을 가능성이 큰 것으로 보여집니다. 버스 정보 시스템을 구축하고 데이터를 수집해서 공개하려면 각종 장비들이 필요한데, 일괄적으로 한번에 설치하기에는 비용 문제에 걸릴 수 있는 것입니다. 광역시와 도 간의 데이터 격차가 가장 현저하게 나타나는 부문이었습니다.
As we have seen so far, each municipality has built a public data portal, uploaded many kinds of data, and is making efforts to open up public data. However, although the amount of data that is open is gradually increasing, it is rather unsatisfactory in terms of managing the environment and quality so that companies and citizens can freely use the data .
The real significance of public data is that anyone can freely use it and become a means of improving the quality of life. For these ultimate goals, you will have to build user-friendly public data by integrating data formats and sources, and by providing friendly instructions on data update dates, formats, and licenses.
– News 2017-10-25 Jelly anjeongmin
