지난 시간에 우리는 ‘마케팅 분석 실전편 1탄 : 차트에서 데이터의 스토리를 파악하는 법‘에 대해 알아봤습니다. “측정”과 “스토리텔링”이라는 데이터 분석의 목적을 달성하기 위해서는 시각화의 역할이 굉장히 중요했죠.
차트 외에도 데이터의 의미를 파악할 방법이 있을까요?
평소 마케터 여러분들이 데이터를 보는 이유에 대해 생각해봅시다. 데이터 자체가 마케팅 결과이자 자신의 성과이기 때문이죠. 광고 집행 이후 사람들의 반응(노출, 클릭, 전환 등)이 수치적으로 얼마나 나오는지 살펴보며 이 데이터를 다시 비용으로 나누어 ROI(투자 대비 성과)를 계산하기도 합니다.
즉, 마케터는 본인의 성과를 측정하기 위해 끊임없이 원본데이터의 숫자들을 집계하고 분석하고, 다시 그 변화의 정도를 보며 인사이트를 만들어냅니다.
원본 데이터의 집계와 계산을 통해 새로운 의미를 뽑아주는 방법에는 “통계분석”이 있습니다. 뉴스젤리에서는 마케터 여러분께 두 차례에 걸쳐 데이터 분석의 실전이라 할 수 있는 통계분석에 대해 알려드리려 합니다. 그리고 여러 애드테크 솔루션에서 통계 분석 방법들을 활용하고 있는지 알아보겠습니다.
Step 1. 평균이 올랐을때, 기뻐하면 안되는 이유: 표준편차&표준점수 활용해보기
‘표준편차’와 ‘표준점수’라는 말을 들어보셨나요? 표준편차라는 여러 값들이 모인 어떤 데이터가 있을 때, 평균값을 기준으로 데이터가 어떻게 분포하는지를 숫자로 알려주는 값이 표준점수 입니다.
 그림 1 : 표준편차 계산식 (출처 : 위키피디아)
그림 1 : 표준편차 계산식 (출처 : 위키피디아)위의 표준편차 계산식을 쉽게 풀어서 설명해 드릴게요. 평균과 실제 데이터(변인)과의 차이(평균과의 차이)를 제곱한 뒤, 전체 데이터 갯수에서 1을 뺀 숫자로 나눠줍니다(평균은 제외해야 하니까요). 이후 이 숫자(분산)의 제곱근을 구합니다. 간단하게는 엑셀에서 지원하는 수식(stdev)을 활용할 수도 있습니다.
쉽게 말하면, 평균적으로 데이터의 차이가 얼마나 되는지 보여주는 식입니다.
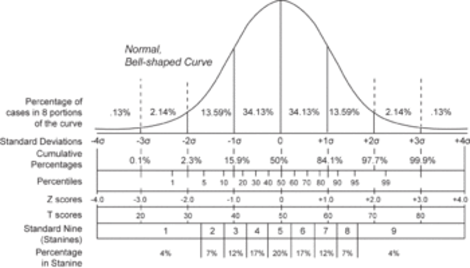 그림 2 : 표준점수의 분포를 나타낸 그림 (출처 : 위키피디아)
그림 2 : 표준점수의 분포를 나타낸 그림 (출처 : 위키피디아)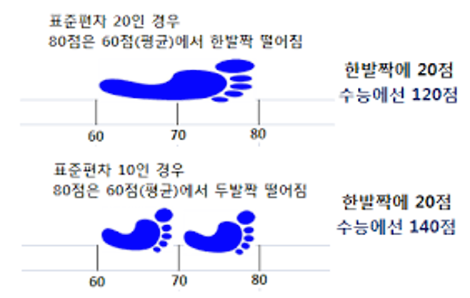 그림 3 : 표준 점수의 원칙을 쉽게 설명해준 그림 (출처 : 네이버 블로그)
그림 3 : 표준 점수의 원칙을 쉽게 설명해준 그림 (출처 : 네이버 블로그)표준편차를 활용하면 각기 다른 특성을 가진 집단에서 얼마나 성과를 거두었는지도 판단할 수 있습니다. 이때 사용하는 점수는 표준점수(Z점수라고 합니다)인데, 특정한 지표가 평균에서 표준편차의 몇 배만큼 떨어져있는지를 판단해주는 기준입니다. 쉽게는 지능검사나 수능 표준점수를 생각하면 됩니다. 각기 다른 과목을 응시한 수험생이 그 집단 하에서 얼마나 잘했는지 상대적으로 비교하는 방식이었죠.
위의 ‘그림 3’을 작년 수능의 영어점수와 수학점수라고 생각해봅시다. 영어 점수는 평균이 60점, 표준편차가 20점이고 수학 점수는 평균이 60점, 10점인 상황에서 어떤 학생이 둘 다 80점이라는 점수를 기록했다면, 상대적으로 수학 점수에서 훨씬 성과가 좋았다 말할 수 있을 것입니다.
그럼 온라인 마케팅 데이터를 분석할 때 표준편차와 표준점수를 어떻게 활용해볼 수 있을까요?
온라인 채널의 광고를 담당하고 있는 여러분이 어제 페이스북에서 10개의 광고를 집행했다고 생각해볼게요. 어제 집행한 페이스북 광고 평균 도달수가 지난주 평균보다 5,000이 증가했습니다. 마케터는 증가한 평균값을 보고 광고의 도달 성과가 굉장히 높아졌다고 판단했을 것입니다. 하지만 실제 성과가 좋아진 것이 아니었습니다. 이대로 보고했다가 팀장님께 꾸중을 들었죠.
자세히 파악해보니 1개 광고 수치의 도달수만 50,000 이상 증가한 상황이었던 것입니다. 이처럼 데이터의 평균값만 보게 된다면, 각각의 값에 대해 파악할 수 없어 성과가 떨어진 것은 알아채지 못할 수 있습니다. 네이버에 1,000개 이상의 광고를 집행하게 된다면, 평균만으로 각 광고 성과 데이터 분포를 완전히 파악하기는 어렵겠죠. 이런 경우에 참고할 수 있는 것이 표준편차와 표준점수에 대한 분석입니다.
마테크 전문 사이트인 ‘Marketing Land’에서 소개한 사례를 통해 이 두 수치를 어떻게 활용할 수 있는지 알려드릴게요.
첫번째, 표준편차는 광고의 효과를 어느정도 보장할 수 있는 수치가 됩니다. 만일 특정 키워드 A의 클릭수 평균이 500이고, 표준점수가 10이라고 하면 500이라는 수치가 어느정도 보장되는 키워드라고 볼 수 있습니다. 반면 키워드 B의 클릭수 평균이 500으로 동일하지만, 표준점수가 50이라고 하면 꾸준한 성과를 내기는 어려울 것입니다.
두번째, 표준점수로 서로 다른 광고 매체들간의 효과를 비교하는 상대 수치로 활용할 수 있습니다. 위에서 언급한 표준점수(Z점수)의 원칙을 광고에 적용해 봅시다. 예를 들면 네이버와 다음의 동일한 키워드 광고를 9:1의 예산 비율로 집행했는데, 각각의 키워드의 효율을 비교해야 한다고 생각해 봅시다. 각자 다른 광고 플랫폼에 다른 예산을 집행했으므로 합계나 평균만을 단순히 비교한다면 이 특징을 반영할 수 없을 것입니다. 그렇다면 각 광고 키워드가 얼마나 좋은 결과를 거두었는지 비교할 수 있는 상대적인 수치가 필요할 것입니다. 표준점수는 이 경우 활용할 수 있는 분석결과가 될 수 있습니다.
Step 2. 어떤 카피의 반응이 더 좋을까? : A/B 테스트로 가설검정 진행하기
어제도 카피 문구 때문에 고민하신 마케터라면, ‘A/B 테스트‘라는 것을 들어보셨을 겁니다. A/B 테스트란 가장 효과가 좋은 광고나 웹페이지를 만들기 위해 구성 요소들을 교체하며 사용자 반응을 테스트하는 기법입니다. 구성 요소의 예시에는 카피, 페이지 레이아웃, 이미지 등이 있습니다. 웹페이지 최적화에서부터 출발한 기법으로, 최근 페이스북에서 분할 테스트라는 광고 테스트에서도 활용되고 있습니다.
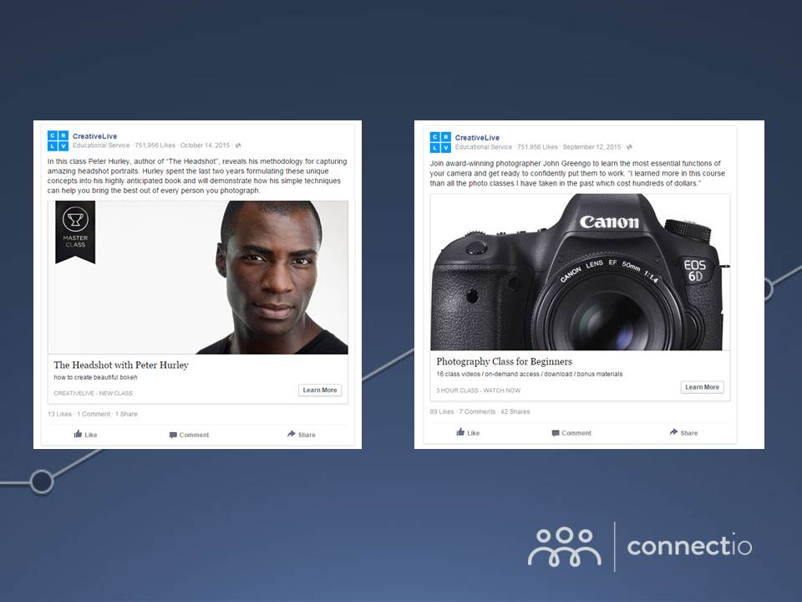 그림 4 : 어느 광고의 결과가 더 좋은지 확인할 수 있는 페이스북 A/B 테스트 (출처 : Connectio)
그림 4 : 어느 광고의 결과가 더 좋은지 확인할 수 있는 페이스북 A/B 테스트 (출처 : Connectio)그렇다면 A/B 테스트 광고를 했을 때 A안을 보여준 고객 5명의 전환 금액이 B안을 본 고객 5명의 전환 고객보다 500원 높으면 B안이 성공적이라고 해석할 수 있을까요?
사실 A/B 테스트를 집행하고 해석할 때 주의해야 할 원칙이 있습니다. A/B 테스트가 추론통계의 원칙을 활용한 방법이기 때문입니다.
가설검정과 신뢰구간이란 주로 “추론통계”에서 쓰이는 말입니다. 앞서 이야기했던 합계, 평균, 표준편차를 통계학에서는 기술통계(descriptive statistics) 방법이라고 합니다. 쉽게 말하자면, 데이터의 특성을 이해할 수 있는 통계방법입니다. 반면 추론통계란 자신의 이론이나 가설을 증명하기 위해 사용되는 방법입니다. 전체 데이터에서 일정한 표본을 추출해서 분석한 뒤, 이를 기반으로 전체 데이터의 특성으로 추론해도 될지 판단하는 것입니다. 즉, 불확실한 무엇인가를 알기 위한 방식입니다.
왜 A/B 테스트에서는 추론통계를 사용할까요? 광고 A안과 B안의 효과를 검증하기 위해 광고를 보여준 고객의 수가 전체 고객의 수가 아니기 때문에, 어느 정도 결과에 대한 추정이 필요합니다. 그리고 “효과가 있다”는 말은 주로 “유의하다(Statistically Significant”)고 사용하게 됩니다.
추론통계를 적용할때의 주의점은 두 가지가 있습니다. 우선 전체 데이터에서 표본을 추출할 때 어느정도 샘플링 숫자를 확보해야 한다는 점입니다. 앞서 언급한 추론통계의 목적은 ‘불확실한 무엇인가를 검증하기 위해서’죠. 샘플링 숫자가 작아진다면 추론통계의 기본 전제를 일반화시키기 어렵게 됩니다. 또한, 샘플링 방법에도 주의를 기울여야 합니다. 샘플링을 잘못하게 되면 데이터의 값이 달라지게 된다는 문제점이 있기 때문입니다.
이 특징은 그대로 A/B 테스트 시 주의사항에도 반영됩니다. A/B 테스트를 잘 집행하기 위해서는 1)샘플 사이즈(광고에 노출되거나 사이트에 접속하는 사람들의 수)가 확보되어야 합니다. 결과의 신뢰도를 확보하기 위해서는, 샘플 사이즈가 확보되어야 합니다. 예를 들어, 전환율 1%를 높이는 디자인을 검증하기 위한 최소 표본수는 3,076명입니다. 2)그리고 이 고객들이 A와 B안에 고루 할당되어야 합니다.
신뢰 구간의 결과를 해석하기 위해서는, 통계적 유의미도를 확인해야 합니다. 통계적 유의미도가 중요한 이유는 이 실험에서 검증된 원칙을 다른 광고에서도 잘 써먹을 수 있을지에 대한 증거가 되기 때문입니다. 주로 1) 평균 분포가 얼마나 차이가 나는지 2) 이 결과를 얼마나 확신할 수 있을지를 살펴보게 됩니다.
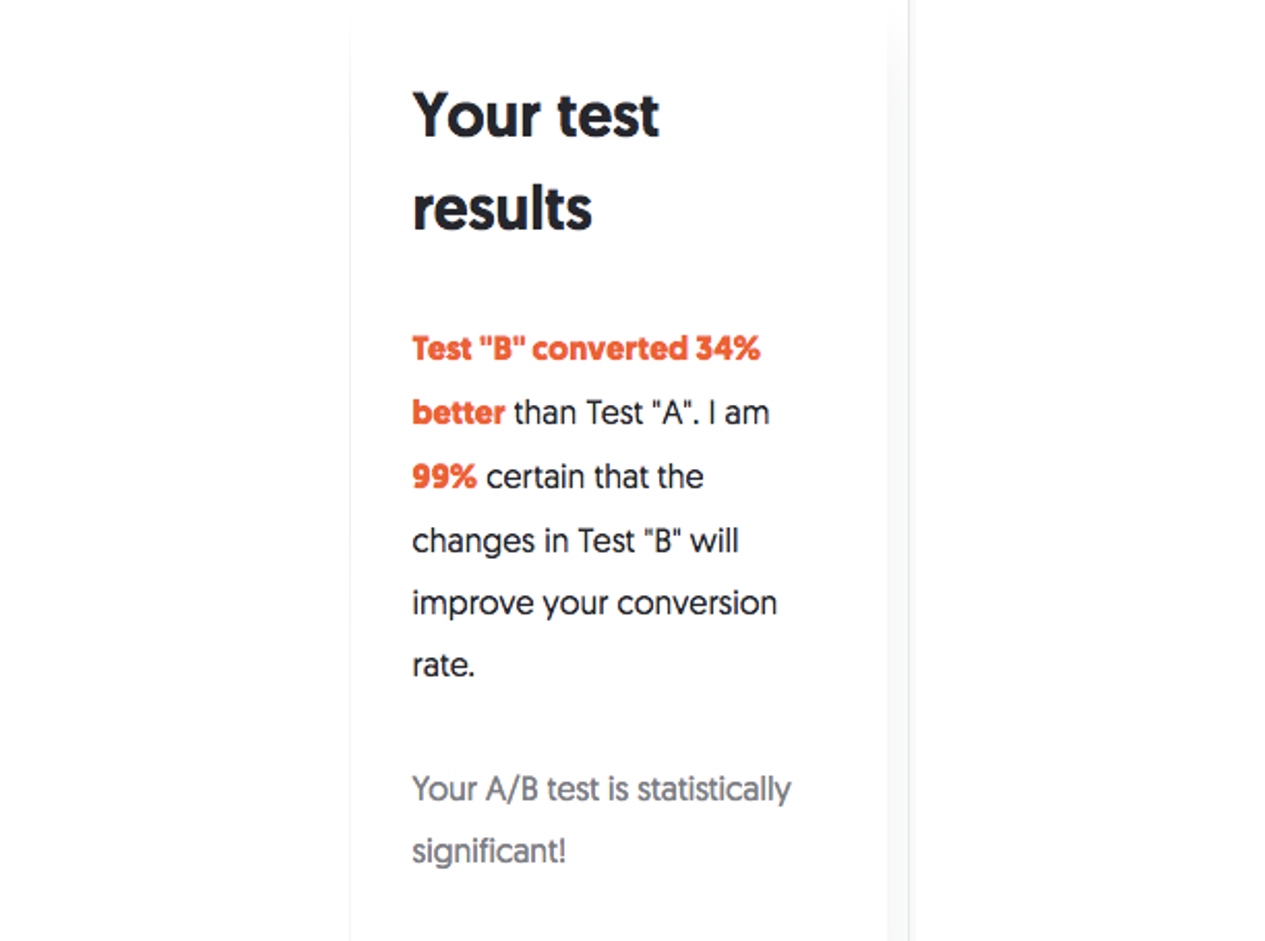 그림 5 : A/B 테스트 결과를 쉽게 전달해주는 닐 파텔의 사이트 (출처 : NEILPATEL)
그림 5 : A/B 테스트 결과를 쉽게 전달해주는 닐 파텔의 사이트 (출처 : NEILPATEL)예컨데 마테크 전문가인 닐 파텔의 A/B 테스트 결과를 볼까요? “테스트 B의 전환이 34% 더 좋았습니다(평균 분포의 차이). 테스트 B에서 시도한 변화가 전환율을 높일것이라고 99% 확신합니다(통계 유의도)” 라고 좀더 쉽게 전달해줍니다.
이 결과를 엑셀에서 계산하기 두렵다면, 인터넷의 다양한 계산기를 이용해보세요. 광고나 웹사이트 개선 실험 시 사용해볼 수 있겠죠? 아래의 사이트들을 참고해 보세요.
· A/B 테스트와 신뢰구간의 원리를 잘 설명한 사이트
· A/B 테스트에서 필요한 방문자 수를 결정 가능한 사이트
· A/B 테스트 결과를 쉽게 해석해주는 닐 파텔의 사이트
지금까지 통계의 기초 원리를 활용해 마케팅 데이터를 분석할 수 있는 두 가지 방법을 알려드렸습니다. 다시 요약하자면, 분산을 통해서는 마케팅 성과의 분포를 알 수 있었고, 가설검정을 통해서는 마케팅 카피나 이미지 등의 효과를 파악해볼 수 있습니다.
다음 시간에는 실제 통계에서 사용하는 여러 분석 방법을 소개해 드리겠습니다. 데이터의 상관관계를 분석하거나, 과거의 데이터를 예측할 수 있는 방법을 알려드리겠습니다. 다음 글도 기대해주세요:)

