시각화 개념과 원리 이해하기
누구나 데이터를 활용할 수 있는 가장 쉬운 방법은 데이터 시각화 차트로 만드는 것입니다. ‘데이터 시각화’라고 하면 다소 거창해 보일 수 있지만, 우리는 누구나 한 번쯤 데이터 시각화를 한 경험이 있습니다. 수학 교과 과정, 대학과 직장 등에서 보고서, 발표 자료를 만들었을 때를 생각해보면 쉽게 고개를 끄덕이게 될 것입니다.
그렇다면 누구나 한 번쯤 해본 경험이 있을 만큼 쉬운 데이터 시각화를 여러분은 어떻게 하고 있나요? 매일 똑같이 그리는 막대 차트가 지루하게 느껴지지는 않나요? 막대 차트말고 만들 수 있는 차트는 무엇이 있을까요? 전달하고 싶은 데이터 분석 결과를 효과적으로 보여주기 위해 어떤 시각화 차트를 사용하는 것이 가장 적합한 것인지 알고 있나요? 데이터 시각화를 어떻게 해야 더욱 효과적으로 활용할 수 있을까요?
이와 같은 질문에 대한 답은 단연 ‘시각화 원리에 대한 이해’가 전제될 경우 쉽게 찾을 수 있습니다. 그리하여 오늘은 데이터 시각화를 만들기 이전에 먼저 알고 있으면 무조건 좋을 ‘시각화 원리’에 대한 이야기를 하고자 합니다.
시각화 차트를 만들기 위해서는 데이터가 필요합니다. 이를 위해 필요한 데이터에 대해 알아봅시다. 여기에서 이야기하는 데이터란 흔히 볼 수 있는 ‘통계표’가 아닌 ‘로우(raw) 데이터’를 말합니다.
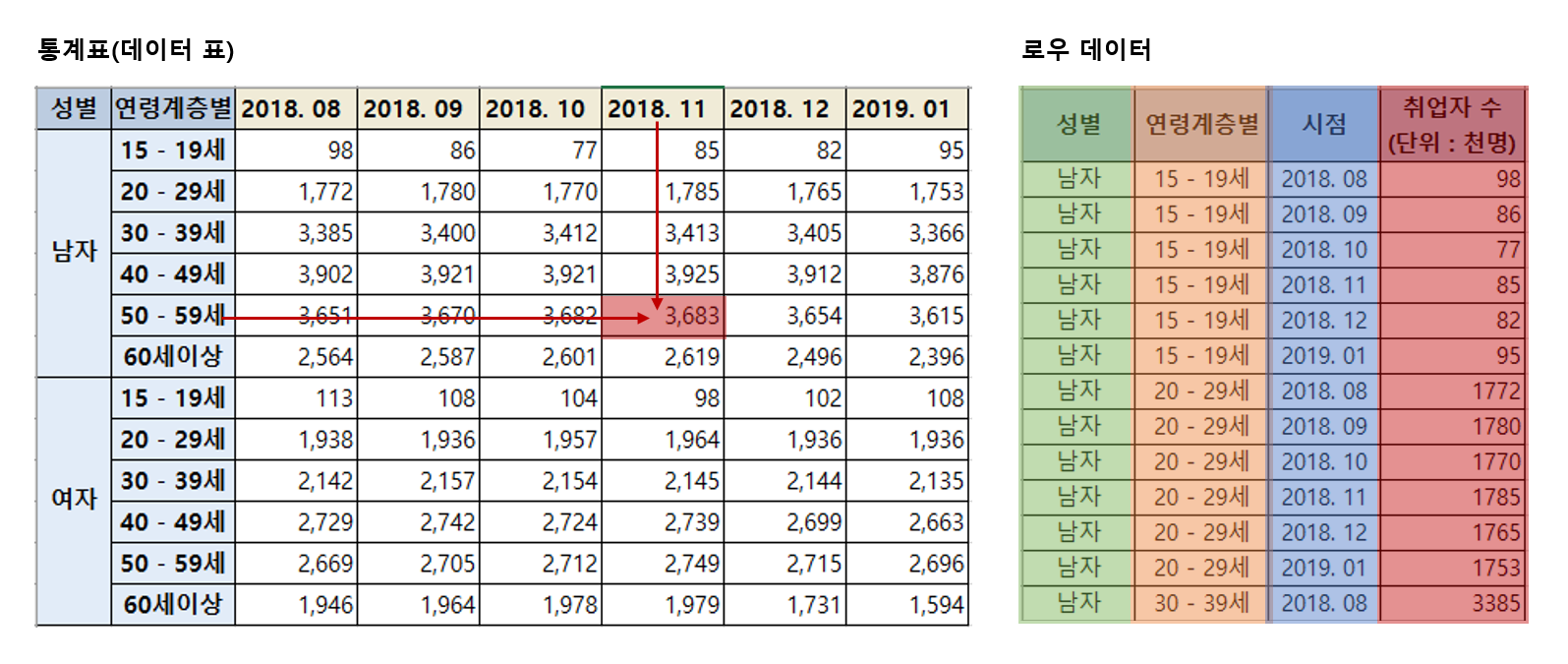
로우 데이터는 하나의 열(column)에 해당 열의 값만 포함하는 형태를 보입니다. 이는 엑셀의 피봇 테이블(Pivot Table)의 형태를 보이는 통계표와 구별됩니다. 다수의 보고서, 발표자료에 ‘데이터’라고 제시된 자료는 로우 데이터가 아닌 통계표인 경우가 많습니다. 통계표는 로우 데이터를 특정한 기준으로 조합 및 계산한 결과물입니다. 로우 데이터를 통계표로 만드는 과정은 시각화 차트를 만드는 과정과 같습니다. 따라서 통계표를 시각화 차트 유형 중 하나로 보는 것이 일반적입니다.
그렇다면, 로우 데이터로 통계표를 만드는 방법이기도 한 시각화 원리는 무엇일까요? 로우 데이터로 시각화 차트를 만드는 방법은 ‘로우 데이터를 특정한 기준으로 조합하고, 계산한 결과를 시각화 요소를 활용해 표현하는 것’입니다.
보다 자세히 알기 위해, 위에 언급한 시각화 원리의 개념을 단계별로 쪼개어 살펴보도록 하겠습니다. 도대체 1) 특정한 기준으로 데이터를 조합하는 것은 무엇이고 2) 계산은 어떻게 하는지, 또 그 결과를 3) 어떻게 시각화 결과물로 표현하는지 알아봅시다.
Q1. 특정한 기준으로 데이터를 조합한다는 것은 무엇을 의미하나요?
앞서 요약적으로 언급한 ‘특정한 기준’이란 로우 데이터의 수많은 데이터 열(column) 중 시각화 차트를 만드는데 활용할 몇 개의 열(column)을 선택하는 것을 의미합니다. 로우 데이터에 아무리 많은 데이터 열(column)을 갖고 있더라도, 하나의 시각화 차트를 만드는데 모든 데이터 열을 활용할 수는 없습니다. 이에 따르면 데이터 시각화의 장점으로 언급되는 ‘많은 양의 데이터를 하나의 차트로 요약한다.’라는 말은 정확히 설명하면 ‘많은 양의 데이터 중 특정 데이터 열을 기준으로 요약해 하나의 차트로 표현한다.’고 할 수 있습니다. 정리하면, 우리는 시각화 차트를 만들기 이전에 활용할 데이터 열을 선택해야 합니다.
그렇다면, 데이터 열은 정확히 무엇인지, 자세히 알아봅시다. 데이터 열은 유사한 의미의 영어 단어로 ‘dimension’, ‘attribute’, ‘field’라고 불리기도 합니다. 한글로는 ‘변수’, ‘차원’으로 주로 이야기 합니다. (저는 지금부터 데이터 열을 변수라고 칭하겠습니다!)
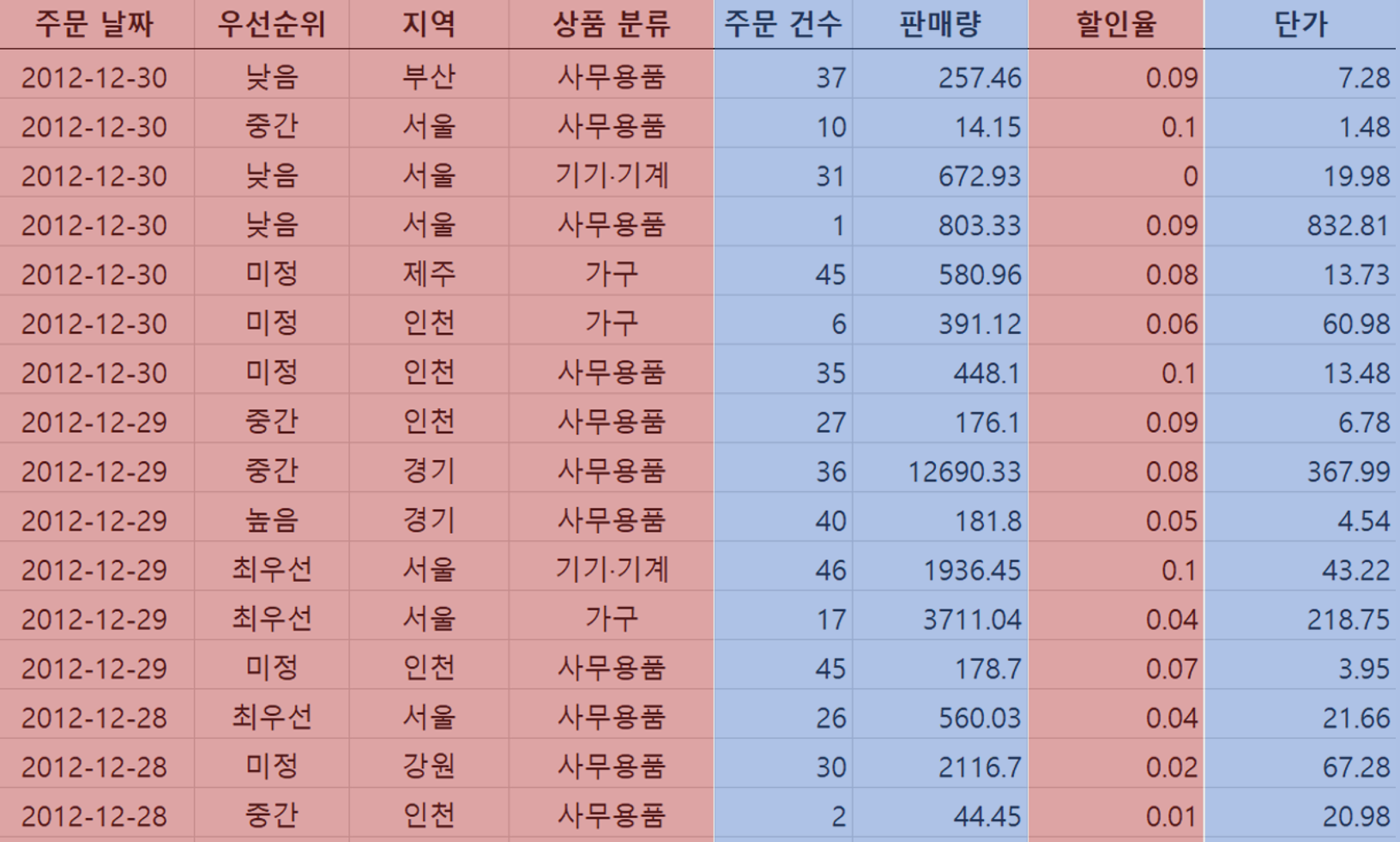
로우 데이터의 변수는 값의 형태에 따라서 2가지 종류 – 수치형 변수, 범주형 변수 – 로 구분할 수 있습니다. 수치형 변수(measure, value)는 계산이 가능한 숫자 형태의 값을 가진 변수를 의미합니다. 반면, 범주형 변수(dimension)는 데이터값이 개별 항목(category)으로 구분되는 데이터를 가진 변수를 의미합니다. 범주형 변수는 크게 4가지 유형 – 1) 텍스트, 2) 지역, 3) 날짜, 4) 숫자 -으로 구분할 수 있습니다. 여기서 한 가지 ‘숫자 형태의 값이라면 수치형 변수가 아닐까?’ 하는 궁금증을 떠올리게 되는데요! 예외적으로 숫자 형태의 값을 갖는 변수라고 할지라도 데이터의 의미상 수학적 계산이 무의미한 경우 해당 변수를 범주형 변수로 활용하는 경우가 종종 있습니다. 대표적인 예로 ‘나이(age)’를 들 수 있습니다.
시각화 차트를 만드는 과정은 로우 데이터 중 특정 변수를 선택하는 것으로부터 시작됩니다. 어떤 수치형 변수와 범주형 변수를 선택하느냐에 따라서 만들 수 있는 시각화 차트 유형이 달라지고, 도출할 수 있는 데이터 인사이트도 달라집니다.

우리는 ‘데이터 안에서 무엇을 알고 싶은지’를 기준으로 변수를 선택하고 차트를 만듭니다. 예를 들어 위 이미지의 데이터를 바탕으로 지역별 판매량이 알고 싶다면, 범주형 변수인 ‘지역’ 변수’와 수치형 변수인 ‘판매량’을 선택합니다. 이처럼 데이터 인사이트 도출을 목적으로 변수를 선택하는 것을 데이터 분석의 관점에서는 데이터 탐색 기준을 설정하는 것으로 볼 수 있습니다. 그 결과로 만든 시각화 차트의 시각적 패턴을 근거로 인사이트를 도출하는 것을 시각적 분석(Visual Analysis)이라고 합니다.
Q2. 선택한 변수는 어떻게 계산하나요?
앞서 언급하였듯이 대부분의 시각화 차트는 범주형 변수, 수치형 변수의 조합으로 만들어집니다. 이때 두 종류의 변수를 서로 다른 방식으로 계산합니다. ‘계산’이라고 하면 ‘숫자만’ 계산하는 것으로 생각할 수 있지만, 시각화 차트를 만들기 위해서는 수치형 변수뿐만 아니라 범주형 변수도 계산해야 합니다. 시각화 분야에서는 이 과정을 데이터 집산(Data Aggregation)이라고 말합니다.
범주형 변수의 데이터 집산은 전체 데이터를 해당 변수의 항목(category)을 기준으로 그룹 짓는 것입니다. 반면, 수치형 변수의 데이터 집산은 숫자 형태의 값을 합산, 평균, 중앙값, 빈도수 등의 기준으로 계산하는 것을 의미합니다. 범주형 변수 1개, 수치형 변수 1개로 데이터 집산을 할 경우, 먼저 전체 데이터를 범주형 변수의 항목으로 그룹 짓고, 해당 그룹별 수치형 변수의 데이터 값을 계산하게 됩니다. 아래의 예를 통해 이해를 더해보도록 하겠습니다.
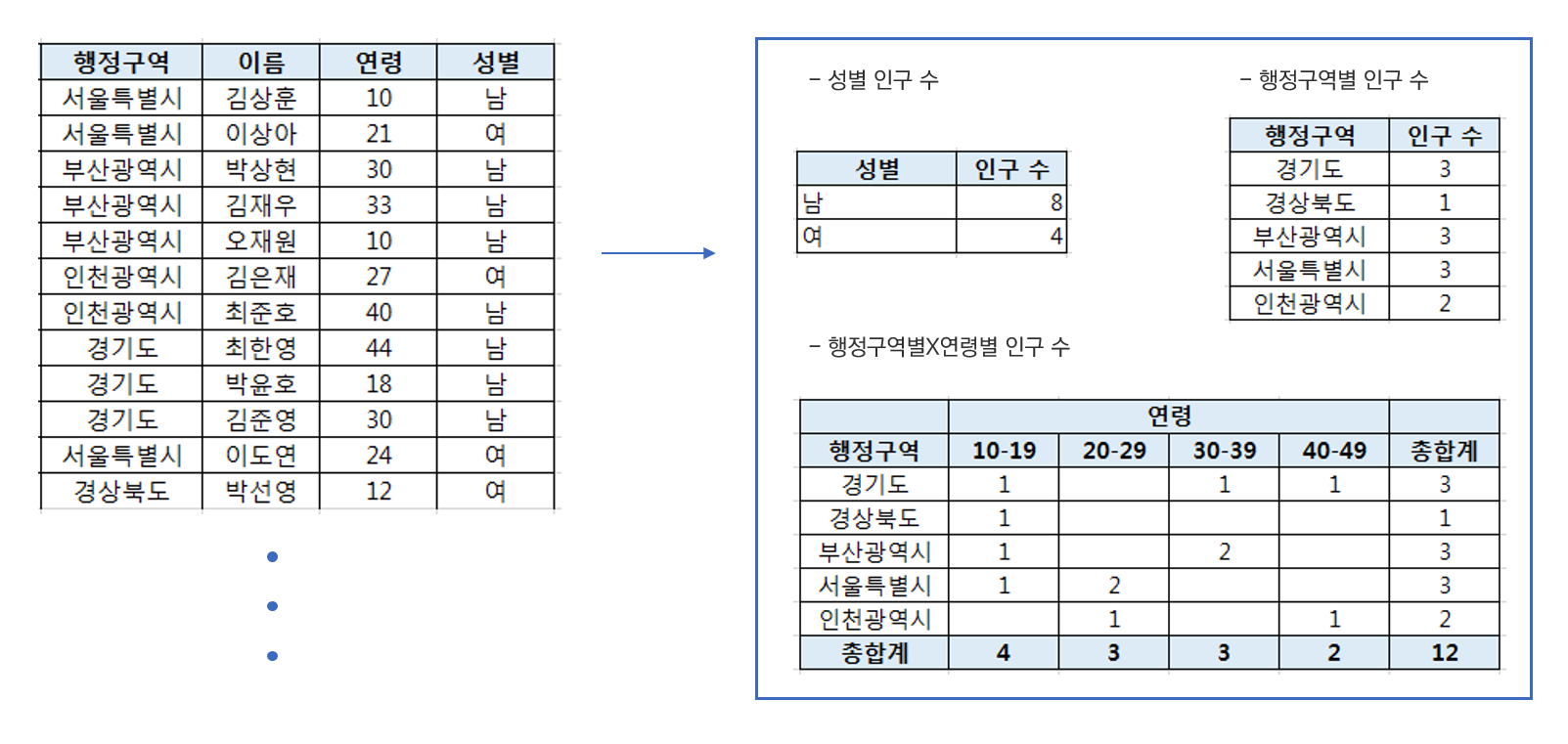
위 이미지는 로우 데이터 중 범주형 변수 1개를 활용하여 전체 데이터를 항목별로 그룹 짓되 그 행의 수를 세는 방식인 ‘빈도수’를 기준으로 데이터 집산한 결과를 통계표로 만든 것입니다. 가장 먼저 성별 인구수 통계표는 전체 데이터를 ‘성별’ 변수의 항목 값인 ‘남’, ‘여’로 구분하고, 해당 값을 가진 행의 수를 센 것을 의미합니다. 행정구역별 인구수는 전체 데이터를 ‘행정구역별’ 변수의 항목 값인 ‘경기도’, ‘경상북도’, ‘부산광역시’, ‘서울특별시’, ‘인천광역시’로 나누고, 해당 값을 가진 행의 수를 센 것입니다. 마지막으로 행정구역별X연령별 인구수는 전체 데이터를 ‘행정구역별’ 변수의 항목과 연령별 변수의 항목 값을 조합하여 총 20개의 그룹으로 나누고, 각 그룹에 해당하는 행의 수를 센 것입니다. (연령별 변수가 앞서 언급한 수치형 변수를 범주형 변수로 활용한 예로, 여기에서는 수치형 변수 값 그대로 사용하지 않고, 10세를 기준으로 그룹핑한 뒤 활용하였습니다.)
우리는 사례를 통해 범주형 변수를 무엇으로 하느냐에 따라 데이터 집산 결과의 통계표가 다른 것을 알 수 있습니다. 즉, 로우 데이터 하나를 활용하더라도 어떤 변수를 선택하느냐에 따라서 데이터 집산 결과가 달라집니다.
데이터 집산 결과는 어떤 범주형 변수를 선택하느냐, 또 어떤 수치형 변수를 선택하느냐에 따라서 달라집니다. 또 수치형 변수의 집산 기준을 빈도수가 아닌 합산, 평균값, 중앙값 등 어떤 기준으로 하느냐에 따라서도 데이터 집산 결과가 달라집니다. 서로 다른 데이터 집산 결과는 각각의 통계표로 만들 수 있습니다. 통계표 역시 시각화 차트 유형 중 하나이므로, 정리하면 로우 데이터 하나를 활용하더라도 어떤 변수를 기준으로 데이터 집산을 하느냐에 따라서 수많은 차트를 만들 수 있다는 것을 알 수 있습니다. 또 여러 데이터 집산 결과를 같은 종류의 시각화 차트로 만들어도, 각 차트의 시각적 패턴이 달라질 수 있다는 것 역시 알 수 있습니다.
시각적 분석에서 다양한 조합의 변수 선택에 따라 만들어진, 서로 다른 시각적 패턴을 보이는 많은 시각화 차트는 데이터 분석의 관점에서 더욱 다양하고 종합적으로 데이터를 해석하고 인사이트를 도출하는 데 중요한 역할을 합니다.
※ 데이터 집산에 관한 좀 더 자세한 이야기가 궁금하신 분은 아래 글을 읽어보세요.
1. 데이터 집산 개념 이해하기 : 데이터 하나로 몇 개의 차트를 만들 수 있을까요?
2. 수치형 변수의 데이터 집산 : 숫자는 계산하라고 있는 것! 차트 만들기에서도 예외는 아니다.
3. 성별, 연령별, 지역별… 데이터를 나누면 인사이트가 보인다!
Q3. 계산한 데이터로 어떻게 시각화 차트를 만들 수 있나요?
앞서 언급하였듯이 시각화 분야에서 통계표로 표현된 데이터 집산 결과 역시 시각화 유형 중 하나로 보는 것이 일반적입니다. 데이터 집산 결과를 텍스트 형태로 가시화했기 때문입니다. 다만 시각화 원리에 대한 이해가 부족한 경우, 통계표가 도형이나 색을 활용해 표현되지 않았기 때문에, 이를 시각화 유형으로 인지하지 못하는 경우가 많습니다. 통계표 역시 우리가 흔히 알고 있는 막대 차트, 선 차트, 파이 차트 등과 같은 과정에 따라서 만들어진 시각화 결과물로 이해할 필요가 있습니다.
그렇다면, 막대 차트, 선 차트, 파이 차트 등 다양한 시각화 유형은 어떤 차이에 의해서 만들어진 것일까요? 시각화 차트 유형은 데이터 집산 결과를 어떤 형태의 도형으로 활용해 표현하고, 또 색을 어떤 의도로 사용하느냐에 따라서 달라집니다. 아래 사례를 통해 자세히 이해해보도록 하겠습니다.
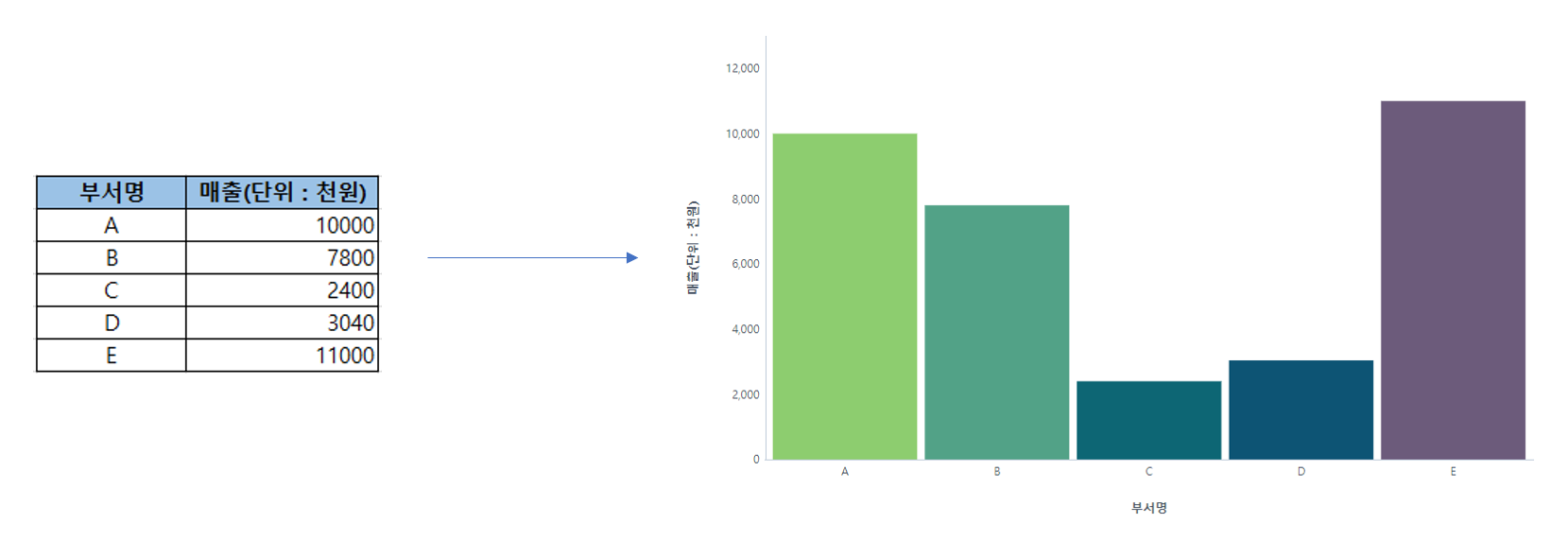
먼저 막대차트를 만들어보겠습니다. 왼쪽의 데이터 집산 결과를 볼까요? 범주형 변수인 부서명별로, 수치형 변수가 계산된 값인 매출 데이터를 확인할 수 있습니다. 이를 막대차트로 만드는 방법은 부서별로 시각화 요소를 개별적으로 그리되, 수치 데이터의 크기를 막대의 길이로 표현한 것입니다. 우리는 막대 차트에서 막대의 길이를 기준으로 데이터의 크고 작음을 직관적으로 비교하여 데이터 인사이트를 도출할 수 있습니다. 위 막대 차트에서의 색은 범주형 항목을 빠르게 구분하기 위한 목적으로 사용되었습니다.
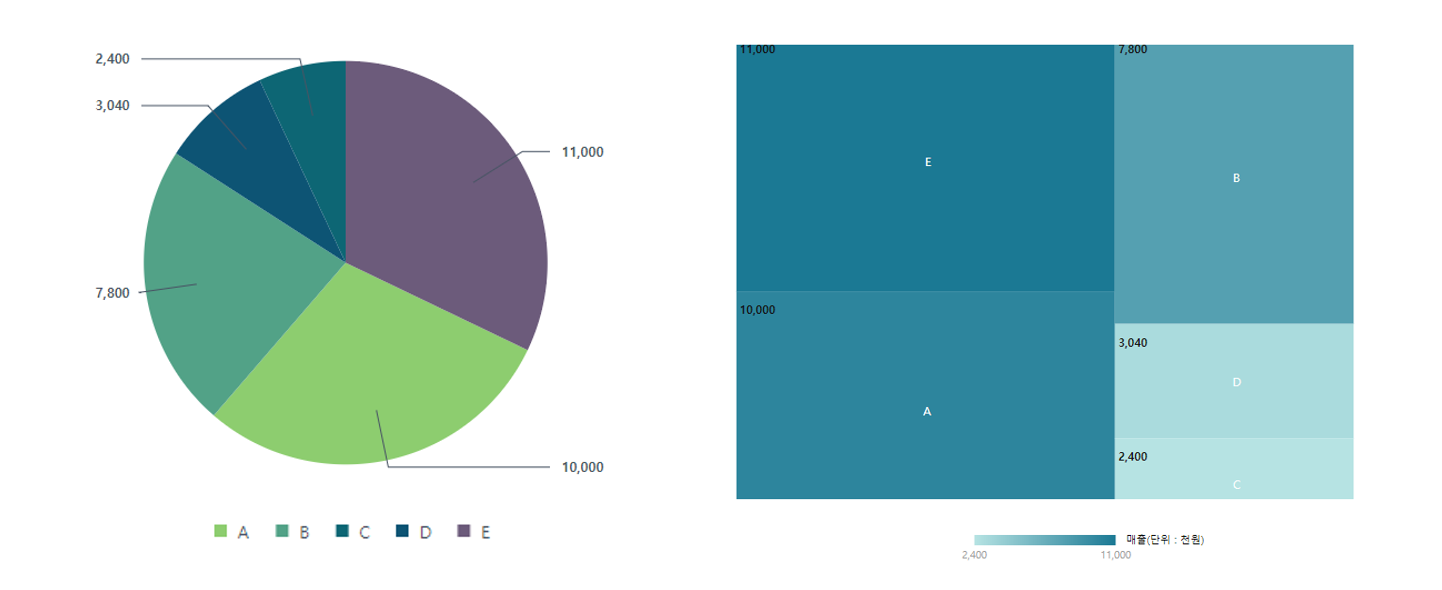
같은 데이터 집산 결과를 활용하여 파이 차트와 트리맵(tree map) 시각화도 만들 수 있습니다. 파이 차트는 하나의 원을 회사의 전체 매출로 보고, 매출을 기준으로 부서별 조각의 크기를 달리 표현한 것입니다. 이 경우 역시 막대차트와 동일하게 범주형 항목을 빠르게 구분하기 위해 부서별로 다른 색을 사용하여 표현하였습니다. 트리맵은 회사의 전체 매출을 사각형 영역으로 표현하되 그 안의 조각을 부서별 매출의 크기에 따라서 달리 표현한 것입니다. 트리맵의 경우 조각의 크기뿐만 아니라 색 역시 데이터 크기를 보여주기 위한 목적으로 활용한 것이 차이입니다.
위 사례를 통해 우리는 데이터 집산 결과가 시각화 차트로 만들어지는 과정을 이해할 수 있는 동시에 같은 데이터 집산 결과를 활용하더라도 다양한 시각화 차트로의 표현이 가능하다는 것을 알 수 있습니다. 위 사례에서 본 막대 차트, 파이 차트, 트리맵 모두 범주형 변수 1개와 수치형 변수 1개의 조합에 따라 만들어진 시각화 차트이며, 이 외 다양한 시각화 차트 유형도 각각을 만드는데 활용할 수 있는 데이터 변수 조합이 정해져 있습니다.
그렇다면, 여기에서 한 가지 궁금증이 들 텐데요! 같은 데이터 집산 결과로 다양한 시각화 차트를 만들 수 있다면, 도대체 어떤 시각화 차트를 사용하는 것이 가장 효과적일까요? 효과적인 차트를 결정하는 방법은 시각화 차트를 어떤 목적으로 활용할 것이냐에 대한 차트 제작자의 답에 따라서 달라집니다. 즉, 시각화 차트 제작자는 차트를 통해 전달하고자 하는 메시지가 무엇인지 알고, 이에 따라 적합한 시각화 차트 유형을 선택해야 합니다.
시각화 차트 유형을 선택하는 기준은 그 목적에 따라 크게 5가지 정도로 구분할 수 있습니다.

시각화의 기본적인 목적인 ‘비교’를 위해서는 막대 차트, 버블 차트 등을 사용합니다. ‘시간 흐름에 따른 데이터의 변화’를 보기 위해서는 선 차트, 영역 차트, 타임라인 차트, 간트 차트 등을 사용합니다.
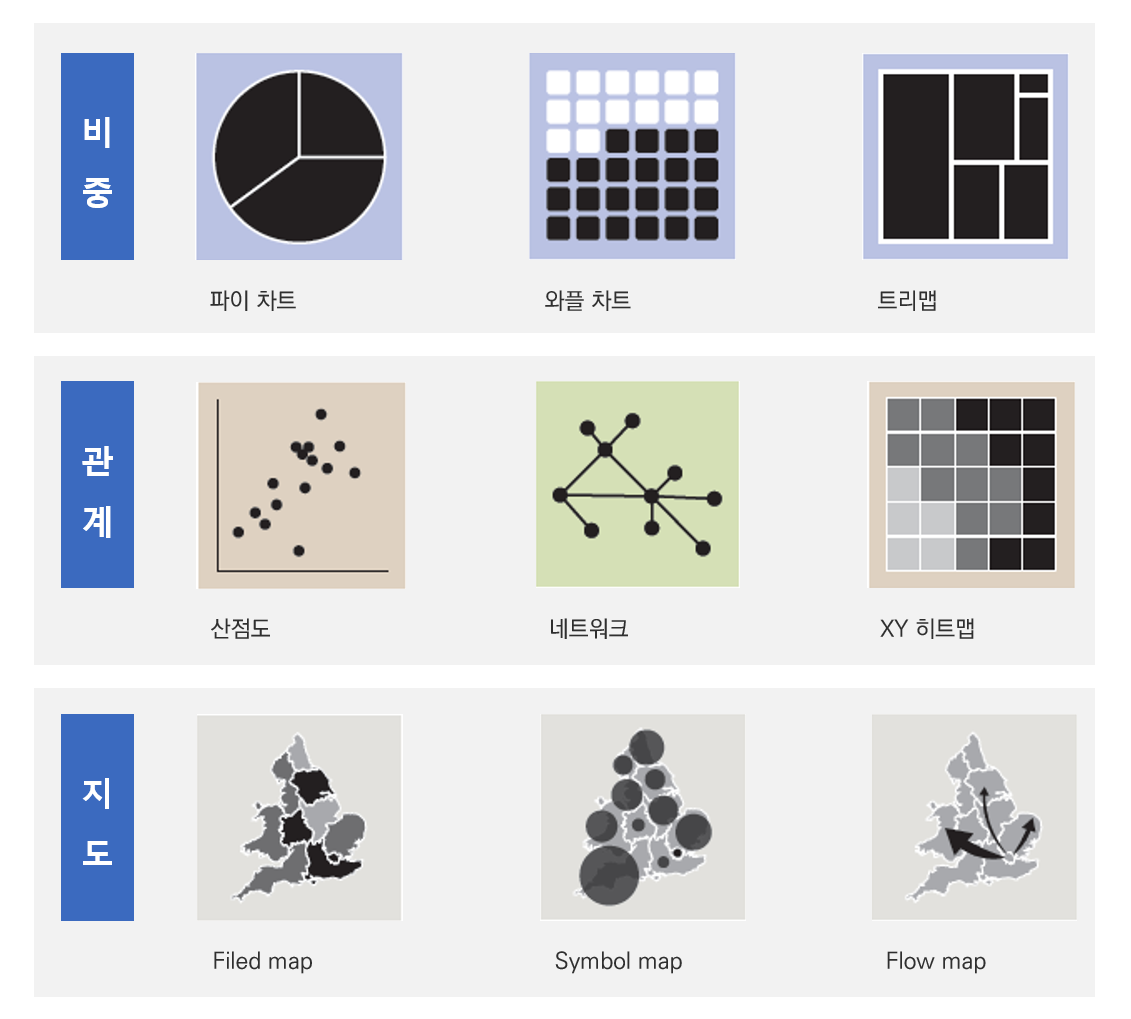
전체 데이터 중 특정 항목이 차지하는 ‘비중’을 보기 위해서는 파이 차트, 와플 차트, 트리맵 등을 활용하고 데이터 간의 관계를 보기 위해서 산점도, 네트워크 시각화 유형을 활용합니다. 위치 데이터를 포함한 경우, 다양한 지도 시각화 유형을 활용하면 지리적 배경 정보를 종합한 데이터 인사이트를 발견할 수 있습니다.
지금까지 로우 데이터의 특정 변수를 기준으로 조합한 데이터 집산 결과를 시각화 요소로 표현하는 데이터 시각화 원리에 대해 자세히 알아보았습니다. 우리가 사용할 수 있는 많은 시각화 도구들은 본문에서 언급한 범주형 변수와 수치형 변수 개념을 직접 명시하고 시각화 원리에 따라 차트를 만들어주기 때문에, 이에 대한 정확한 이해가 전제된다면 어떤 시각화 도구를 사용하더라도 쉽게 시각화 차트를 만들 수 있습니다.
더불어 시각화 원리에 대한 정확한 이해는 차트를 만드는 사람뿐만 이나라 다른 사람이 만든 차트를 보는 사람에게도 필요한 부분입니다. 왜냐하면, 다양한 시각화 차트가 각각 어떻게 만들어지는지, 또 어떤 목적으로 주로 활용하는지 알고 있을 때, 정확히 데이터를 해석할 수 있고, 또 오류가 있는 차트는 아닌지 구별해낼 수 있기 때문입니다. 더군다나, 모든 차트 유형 각각의 장단점을 갖고 있기 때문에, 시각화의 원리와 차트에 대한 이해를 전제로 할 때 정확한 시각적 분석과 데이터 인사이트 도출을 할 수 있습니다. 데이터 활용 역량이 중요하게 요구되는 지금, 데이터 시각화를 통해 누구나 데이터 활용 경험을 갖길 바라며, 글을 마무리합니다.
By 브랜드마케팅팀 강원양
