Hello, this is news jelly.
This foreign article is related to public data.
<COMPUTERWORLD>
Lukas Biewald
Articles dated March 16, 2015
We need open data to be a new open source
The open source movement is one of the most powerful forces advancing technology. Start-up companies have made huge money with venture capital. Any small start-up today has access to the best tools in the world.
However, the lack of open data is still seriously slowing innovation, and as data becomes more and more critical, the problem is getting worse.
For example, consider how difficult it would be for an innovative forecasting analyst to start smoothly. It’s hard not because they do not have software, but because there is no data. There are already a few excellent open source projects, but the lack of available data is a big problem when testing or training algorithms in any domain.
The same is true when managers start eCommerce. High-level search engines are very important in e-commerce, and they have enough tools to build a good search infrastructure like Lucene. However, it is a reality that there is no relevant set of data that can be tested and trained.
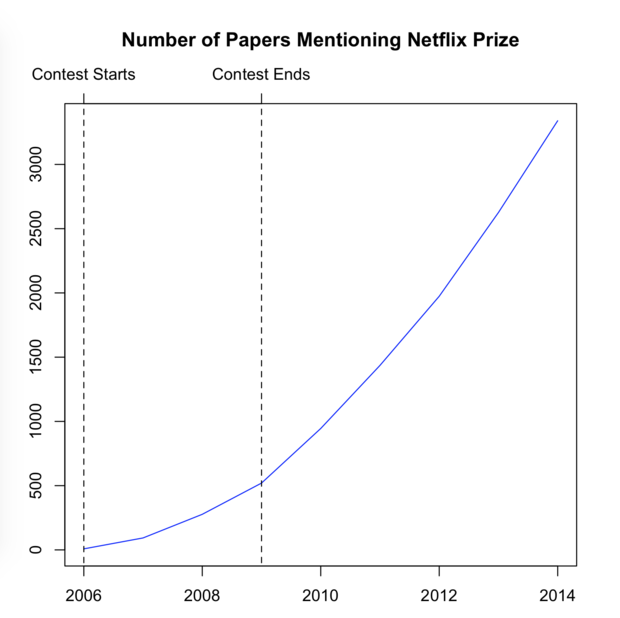
This is what I want to say. There are a lot of data engineers out there who do not have the tools to do smart, creative but worthwhile work. Do you remember that Netflix opened the contest for the movie aggregation algorithm? Numerous solutions were submitted, all based on data bundles with 100,000,000 lines. Netflix ultimately gave the $ 10,000 prize to a team of data engineers who won their algorithms.
Five years after its award, Netflix’s data set is still used in computer science research. More than 3000 papers have mentioned it. And most of the paper was written after the contest was over. This is not because movie data is important to computer science research. However, there is no good quality available data set. The contest was not important. It is a real value to distribute the data to the world.
Personally, I would be happy if I could use Netflix ‘s data in my college or my first start – up. There is not a lot of data in the real world. In fact, our research is often based on possible sets of data, and most of the data is very small or less relevant to the real world.
And the reality is that it is still difficult for students or researchers to conduct research on big data, as most of the big data sets are now locked in the company’s data warehouse.
All of these problems can be solved by having a lot of bigger and bigger data. This will help the startup to train the algorithm. It will also allow researchers to get more data on important issues such as cyber bullying and the speed of disaster response. This will be a great help in making really good software easier.
It is interesting that the government has begun an effort to distribute data like data.gov. Amazon provides free and interesting data sets, and universities like UC lrvine are also releasing valuable data sets in their labs. Start-ups like Enigma.io also appeared to help companies use public data.
Nevertheless, what we need most is for companies to start sharing commercial data sets, as seen in the open source data project. If a small number of companies start this movement, the benefits will encourage another participation and we will be able to achieve enormous innovation.
News jelly that delivers quick news with big data, public data, and social data
