데이터는 뉴스, 기사, 보고서, 발표 자료 등 다양한 분야에서 시각화의 형태로 자주 활용되고 있습니다. 데이터 시각화가 데이터 안의 숨겨진 유의미한 의미를 쉽고 빠르게 찾을 수 있도록 돕기 때문인데요. 하지만 이는 잘 정제된 데이터가 준비되어 있다는 것을 전제로 합니다. 그렇다면 데이터 시각화를 위해 필요한 잘 정제된 데이터란 무엇이며 어떻게 정제해야 할까요?
표 형태의 데이터와 원 자료(Raw data)의 차이

우리가 일반적으로 알고 있는 데이터는 어떤 모습일까요? 주로 표 형태의 자료를 볼 수 있는데요. 표 형태의 자료들은 통계적으로 처리되지 않은 원 자료(Raw data)가 아니라 원 자료를 특정 조건에 따라 계산하여 정리한 통계 데이터를 보기 쉽게 정리한 것입니다. 그래서 표에서 값을 나타내는 하나의 셀(cell)은 여러 개의 변수 정보를 포함합니다. 하지만 시각화를 위해서는 원 자료 혹은 통계 데이터와 같은 형태의 데이터가 필요합니다.
사례를 통해 자세히 살펴보자면, 통계청에서 제공하는 데이터는 표 형식입니다. 국가통계포털에서 ‘연령 및 성별 인구 – 읍면동’ 데이터를 조회하면 값을 나타내는 셀(cell) 하나는 ‘데이터 시점’, ‘행정구역별’, ‘연령별’, ‘성별’ 정보를 모두 포함합니다. 통계청은 인구 현황을 조사한 원 자료에서 3가지 필드 조합에 대한 수치 값을 계산하여, 이를 표로 제공한 것입니다.

그렇다면 시각화에 필요한 원 자료의 형태는 어떤 모습이어야 할까요? 통계청의 ‘연령 및 성별 인구’의 표 형태의 데이터를 바탕으로 원 자료를 만들어 보았습니다. 원 자료는 시점(연도), 행정구역, 이름, 연령, 성별 필드를 갖고 있으며, 필드별 셀 값은 해당 필드의 정보만을 포함하고 있습니다. 통계 데이터는 원 자료의 필드 조합과 수치 값의 계산(합산, 평균, 최대값, 최소값 등)을 통해 만들어 집니다. 예를 들어 ‘2015년 성별 인구 수’라는 통계는 ‘시점(연도)’ 필드의 값으로 ‘2015’를 갖고 있는 행을 ‘성별’ 필드의 값(남, 녀)별로 센(count) 값을 ‘인구 수’로 나타낸 것입니다.
통계청을 포함하여 공공데이터를 제공하는 다수의 기관에서 제공하는 데이터는 통계 데이터인 경우가 많습니다. 원 자료에 대한 공개는 거의 이루어지지 않고 있으며, 간혹 원 자료 형태를 띤 통계 데이터를 제공하는 경우를 볼 수 있습니다. 따라서 공공데이터를 활용하여 시각화를 하려면 데이터 정제가 필요합니다.
시각화를 위해 필요한 데이터 구조

시각화는 숫자, 텍스트로 구성된 방대한 양의 데이터를 한 눈에 파악할 수 있는 장점이 있습니다. 집단 간의 특성을 비교 하거나, 데이터의 시계열 · 공간적 변화 등 시각적 패턴을 쉽게 파악할 수 있습니다. 이런 시각화를 만들기 위해서는 원 자료 형태의 데이터가 필요합니다. 원 자료 형태의 데이터는 형식적으로 행(Row)과 열(Column)으로 구성됩니다. 행은 ‘Item’, ‘Record’, 열은 ‘Attribute’, ‘Field’이라고도 불립니다. 셀(cell)은 행과 열의 조합으로 만들어지며, 각각의 값(value)을 갖습니다.
중요한 것은 데이터의 열(Attribute, Column, Field)은 해당 열의 정보 하나만을 값으로 갖는 다는 것 입니다. 열의 유형(Type)은 2가지로 구분되는데요. 범주형(Categorical)과 순서형(Ordered)입니다. 범주형의 경우 주로 문자 형태의 값을 갖으며 대부분 비교 집단을 만드는 기준이 됩니다.
반면, 순서형은 숫자 형태의 값을 갖습니다. 위 사례의 열을 유형별로 살펴보면, ‘호선명’, ‘역명’ 열이 범주형에 해당하며, ‘승차 총 승객수’, ‘하차 총 승객수’ 열을 순서형으로 볼 수 있습니다. 시각화는 이와 같은 형태의 데이터 중 특정 열을 선택해, 이들의 조합을 시각적으로 나타낸 것을 말합니다.
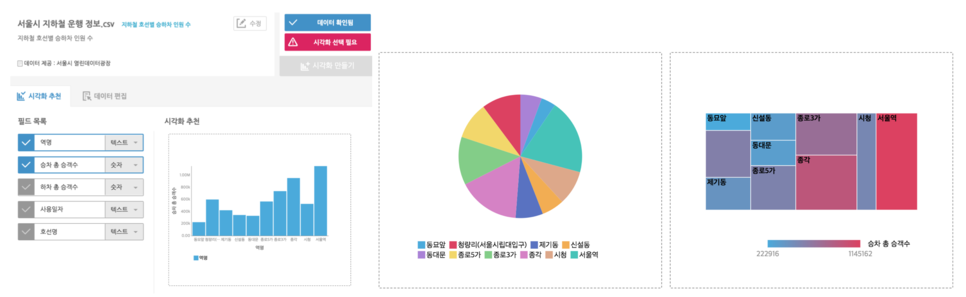
예를 들어 막대 차트는 범주형 열 1개, 순서형 열 1개 선택한 것으로, 각 범주별로 순서형 열의 데이터 값을 막대 길이로 표현한 것입니다. 동일한 조합의 열을 활용하되 순서형 열이 갖고 있는 정보를 파이(pie) 조각의 면적으로 표현하면 파이차트, 사각형 면적으로 표현하면 트리맵(Tree map)으로 그릴 수 있습니다.
시각화를 위해 통계 표 형태의 데이터를 정제하는 방법
공공데이터를 가장 쉽게 찾을 수 있는 통계청은 표 형태로 데이터를 제공합니다. 시각화를 위해서는 하나의 필드에 하나의 의미 정보만 포함한 형태의 데이터로 정제해야 하는데, 통계청 포털에서 제공하는 피봇 옵션을 활용하면 비교적 쉽게 정제 할 수 있습니다.

통계청 포털에서 데이터 조회 후 우측 상단 아이콘 중 화살표 모양을 클릭하면 팝업창으로 피봇 옵션이 나타나고, 현재 표의 행·열 피봇 조건을 확인할 수 있습니다. 데이터 정제를 위해 우측 영역에 있는 필드를 드래그 앤 드롭 하여 좌측 영역으로 이동시킵니다. 좌측 영역으로 이동시킨 필드는 순서를 조정해 활용할 수 있습니다.
피봇 옵션을 수정한 뒤에는 셀 병합을 하지 않은 형태의 파일로 다운로드 해야 합니다. 그렇지 않을 경우 셀 병합을 해제하고 빈 셀의 값을 채우는 과정을 따로 하는 번거로운 과정을 거쳐야 합니다.

통계청 외 공공데이터를 개방하는 포털에서도 통계청의 피봇 옵션과 같은 언피봇(Un-pivot) 기능을 제공한다면, 포털 자체에서 정제된 데이터를 다운로드 할 수 있습니다. 그렇지 않은 경우에는 데이터를 다운로드 한 뒤 이를 사용자가 직접 정제해야 하는데요. 오픈리파인(Open Refine) 등 데이터 정제 툴(tool)을 사용하는 방법이 있습니다.
우리가 흔히 알고 있는 통계 표 형태의 데이터는 시각화에 적합하지 않기 때문에 하나의 열에 해당 열의 정보만을 포함하는 형태의 데이터 즉, 원 자료 (Raw Data) 형태의 데이터가 필요하다는 점을 알아보았습니다. 이렇게 정제된 데이터는 시각화를 위한 준비가 된 데이터로, 특정 데이터의 열을 선택·조합해 다양한 시각화 형태로 표현할 수 있는데요! 바로 정제된 데이터가 시각화에 필요한 이유이기도 합니다. 예시로 들었던 사례 외에도 시각화하기에 적합하지 않은 데이터의 경우, 이번 글을 참고해 데이터를 정제하여 시각화 하는데 보다 유용하게 사용해보셨으면 합니다!
By 브랜드팀 강원양
