텍스트 데이터를 활용한 시각화 콘텐츠 사례 모음
여러분은 하루 동안 자신이 가장 많이 말하고 쓰는 단어가 무엇인지 알고 있나요? 철학자 마르틴 하이데거에 따르면 언어는 존재의 집이라고 합니다. 이는 우리가 세계를 이해하고 경험하는 방식을 언어가 규정한다는 의미인데요. 한 사람이 사용하는 언어가 그 사람 자체를 의미한다는 면에서, 언어도 개인을 정의하는 일종의 지표이지 않을까?라는 생각을 할 수 있습니다.
우리가 일상에서 하는 말을 데이터로 만들고 시각화를 해본다면, 우리는 무엇을 알게 될까요? 나 스스로, 혹은 타인에 대해 더 깊게 알게 되지 않을까요? 오늘은 일상생활에서 사용하고 접하는 언어를 데이터화해 시각화로 만든, 그러면서도 재미있는 인사이트가 담긴 시각화 콘텐츠 사례 세 가지를 살펴보려고 합니다!
1. 당신이 가장 행복했던 순간은? 설문 조사 응답 문장 속 단어를 시각화한 사례
여러분은 가장 최근 행복했던 순간이 언제인가요? 첫 번째로 알아볼 사례는 사람들의 행복했던 순간을 조사한 설문 조사 응답 데이터를 시각화한 콘텐츠 입니다. 미국의 통계학자 Nathan Yau가 만든 “What Makes People the Most Happy” 콘텐츠의 시각화로 인사이트를 알아보겠습니다!
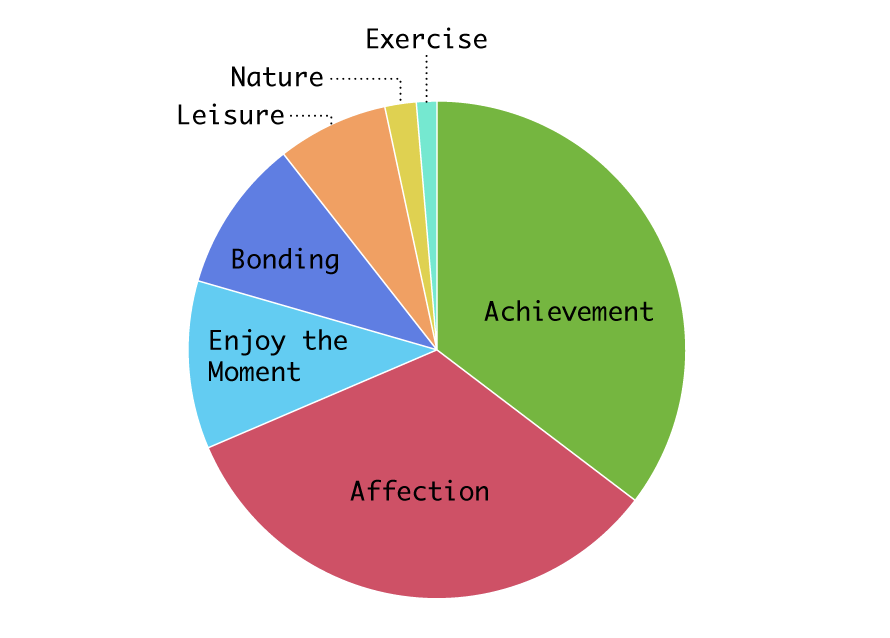
이 콘텐츠는 도쿄대, MIT, 그리고 Recruit Institute of Technology 소속 연구원들이 1만 명의 미국 노동자들을 대상으로 최근에 겪은 행복한 순간을 수집한 데이터셋을 활용했는데요. 설문 데이터셋에는 응답별로 분류된 행복의 유형이 포함되어 있습니다. 위 파이 차트는 행복 유형별 응답 비중을 시각화한 것으로, 가장 큰 비중을 차지한 행복 유형은 연두색 조각인 ‘성과(Achievement)’로 나타났습니다. 그 다음으로 빨간색인 ‘애정(Affection)’, 연한 파란색인 ‘즐거운 순간(Enjoy the Moment)’ 순으로 이어졌습니다.
Nathan Yau는 단순히 행복의 유형을 분류하는 것에서 나아가, 미국 노동자의 응답 문장 자체를 주어, 동사, 목적어로 분리한 뒤, 단어별 행복 유형의 비중을 시각화했습니다. 무엇을 알 수 있는지 함께 살펴볼까요?
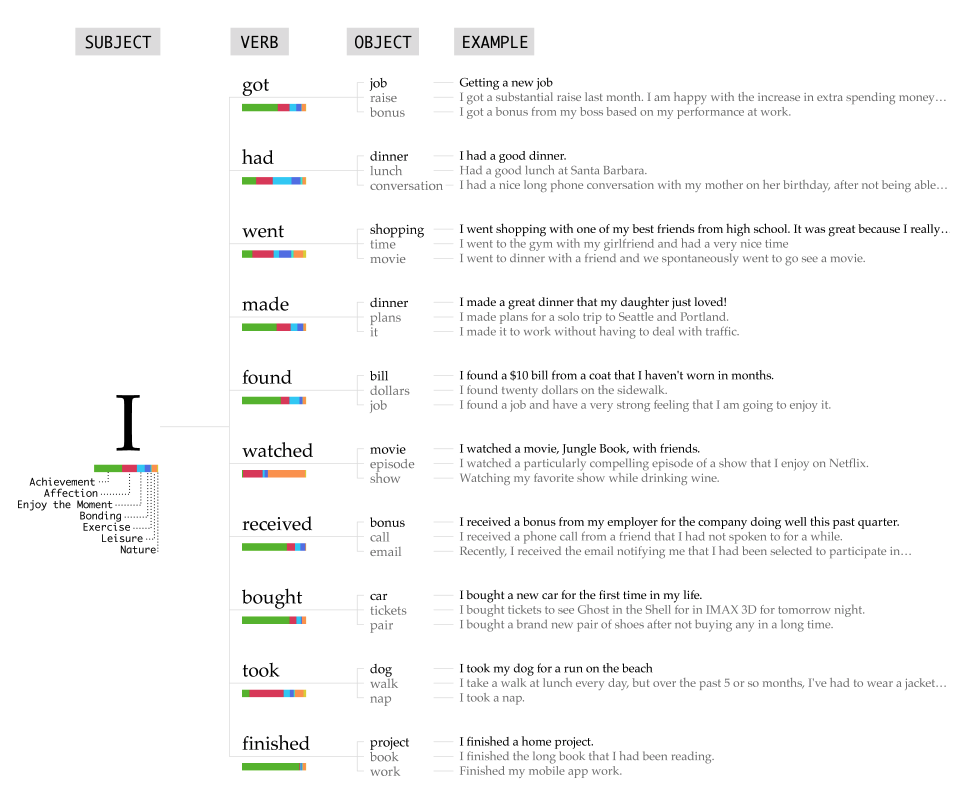
위 이미지는 설문 조사 응답 문장 중 가장 자주 등장한 주어인 ‘나(I)’와 함께 등장하는 동사, 목적어, 그리고 예시 문장 리스트를 나열한 도식화입니다. 주어와 각 동사 하단에는 행복 유형별 비중을 표현한 100% 가로 누적 막대 차트가 있는데요. 차트에 활용된 색상은 앞서 소개한 행복 유형을 의미하고, 각 색상의 비중을 비교함으로써 자신으로부터 나오는 행복 유형 중 어떤 항목이 가장 큰 비중을 차지하는지 파악할 수 있습니다.
‘나(I)’ 하단의 차트를 보면 행복 유형 중 연두색이 의미하는 ‘성과(achievement)’가 가장 많다는 걸 알 수 있습니다. 바로 오른쪽에 위치한 각각의 동사 아래에서도 동일한 누적 막대 차트를 살펴볼 수 있는데요. 동사마다 차이가 있지만, 연두색 막대 길이가 긴 동사들을 다수 확인할 수 있습니다. 행복 유형으로 ‘성과’ 비중이 가장 높은 동사는 ‘마무리했다(finished)’이고, 그 다음으로 ‘받았다(received)’, ‘구매했다(bought)’ 등을 꼽을 수 있습니다.
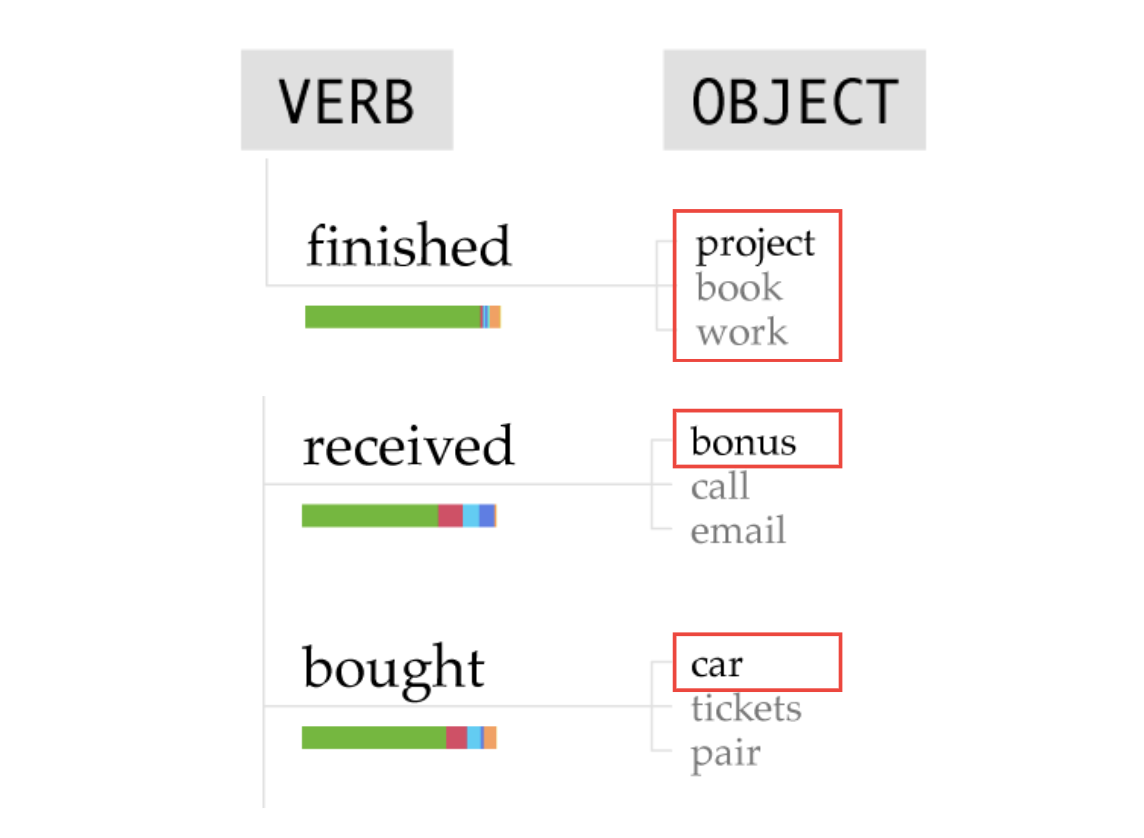
그렇다면 ‘나(I)’는 정확히 무엇을 ‘마무리(finished)’했고, ‘받았고(received)’, ‘구매(bought)’해서 행복했다는 걸까요? 이는 동사 오른쪽에 위치한 목적어 리스트로 살펴볼 수 있는데요. ‘마무리했다(finished)’의 경우 이어지는 목적어가 ‘프로젝트(project)’, ‘책(book)’, 그리고 ‘일(work)’로 나타났습니다. 이어서 ‘받았다(received)’와 ‘구매했다(bought)’는 차례대로 목적어 ‘보너스(bonus)’와 ‘자동차(car)’로 이어지는 걸 확인할 수 있죠.
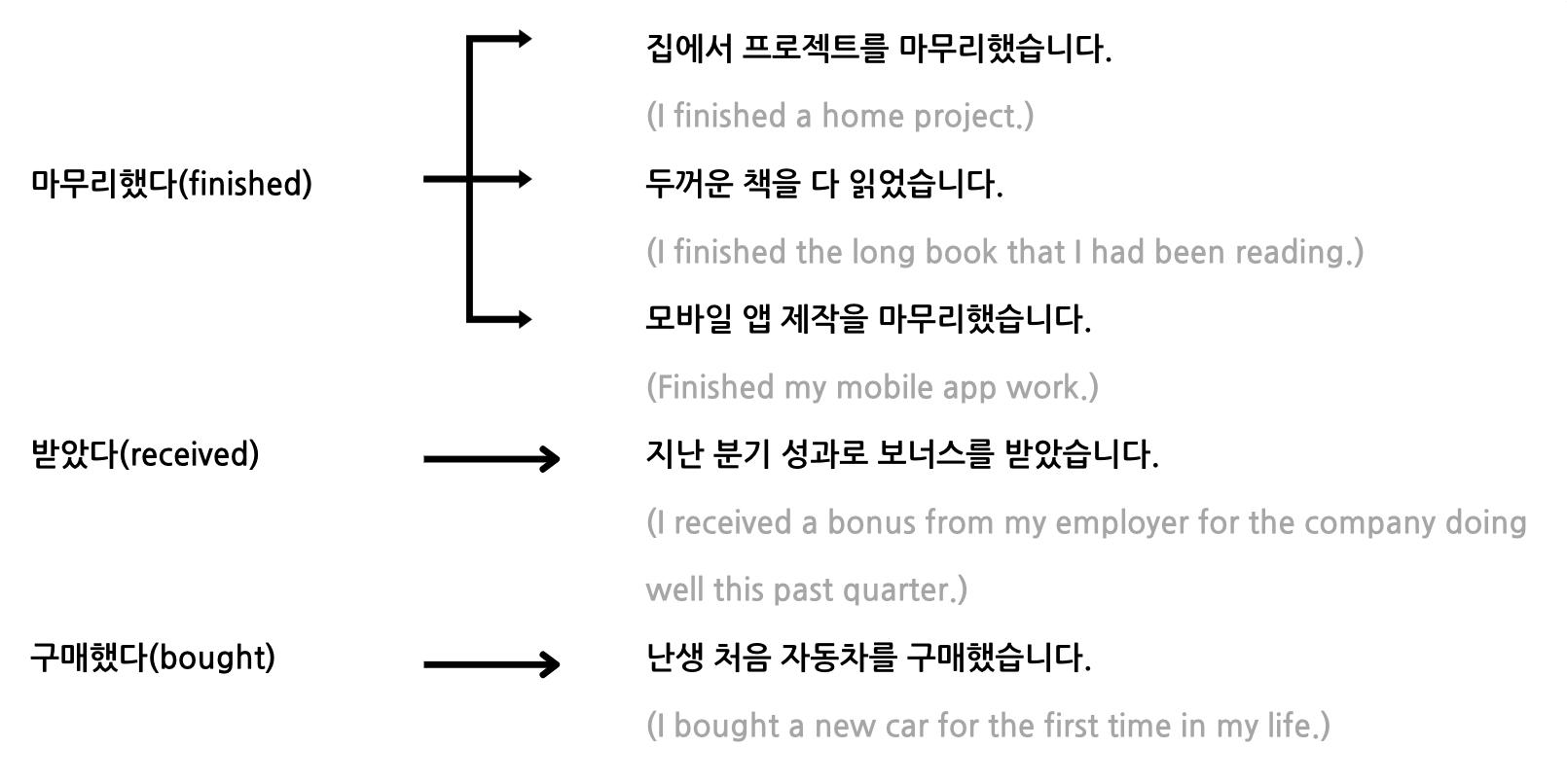
실제 응답 문장을 차례대로 살펴볼까요? 행복한 순간이 담긴 문장은 위 이미지에서 확인할 수 있는데요. ‘마무리했다(finished)’의 경우 집과 관련된 ‘프로젝트(project)’를 마무리했을 때, 두꺼운 ‘책(book)’을 완독했을 때, 그리고 모바일 앱 제작 관련 ‘일(work)’을 마무리한 성과로부터 행복한 순간을 경험했다라고 합니다. ‘받았다(received)’는 지난 성과로 ‘보너스(bonus)’를 받았을 때, ‘구매했다(bought)’는 새로운 ‘자동차(car)’를 구매했을 때 행복했다고 합니다. 이를 종합해보면 꾸준한 노력 끝에 무언가를 완수했을 때의 뿌듯함, 성취나 보상을 한 경험이 ‘나’와 관련된 행복으로 이어지는 것을 확인할 수 있습니다.

‘나(I)’ 중심 문장에서 가장 큰 비중의 행복 유형이 ‘성과’였다면, 다른 주어는 어떨까요? 동일한 구조의 도식화에서 ‘친구(friend)’를 주어로 시작하는 문장을 기반으로 한 번 더 살펴보도록 하겠습니다.
‘친구(friend)’ 단어 하단에 100% 가로 누적 차트를 보면 이전에 살펴본 ‘나(I)’와 다르게 ‘유대감(Bonding)’을 의미하는 파란색 막대가 압도적으로 긴 것을 볼 수 있습니다. 또한 오른쪽 각 동사 아래 누적 막대 차트 역시 파란색이 대부분의 비중을 차지하고 있는데요! 관련 동사로는 ‘왔다(came)’, ‘가졌다(got)’ 등이 있습니다.
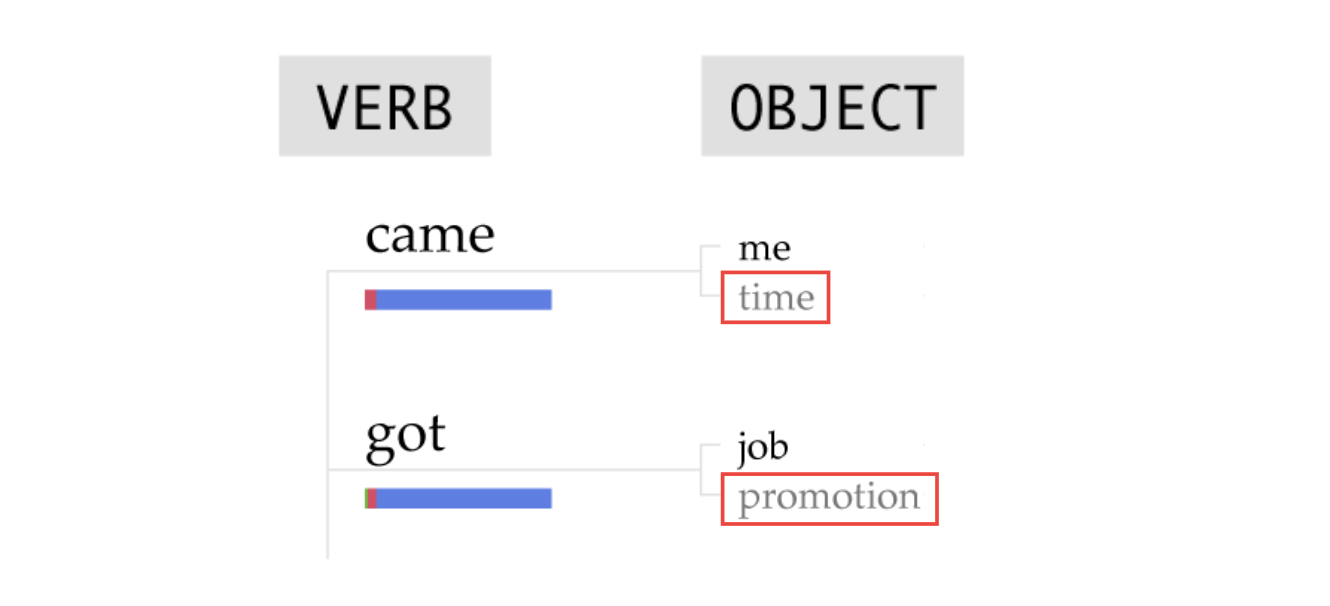
각 동사 이후에 나오는 목적어는 어떨까요? 동사 중 가장 상단에 위치한 ‘왔다(came)’의 경우 목적어로 ‘시간(time)’이 나타났습니다. ‘가졌다(got)’ 동사 뒤에는 ‘승진(promotion)’이 목적어로 등장했습니다.

마찬가지로 이 경우에도 예시 문장을 살펴 보겠습니다! ‘왔다(came)’ 동사가 포함된 행복한 순간의 문장은 오래된 친구가 멕시코의 기념일인 싱코 데 마요(Cinco De Mayo) 중 찾아와서 함께 좋은 ‘시간(time)’을 보냈다는 의미를 포함하고 있습니다. ‘가졌다(got)’의 경우에는 친구가 오랫동안 기다려온 ‘승진(promotion)’을 했다는 소식을 행복한 순간이라고 했는데요. 친구와 함께 시간을 보내거나, 친구에게 좋은 일이 있을 때 기쁜 마음을 갖게 되는 것도 개인의 행복으로 이어지는 것을 알 수 있습니다.
지금까지 살펴본 첫 번째 사례는 행복한 순간을 주제로 한 텍스트 데이터에서 주어와 동사, 목적어를 분리해 각각의 행복 유형별 비중을 표현했는데요. 단순히 행복한 순간의 유형을 정의해보는 것에서 나아가, 우리가 느끼는 행복의 구체적 이유를 텍스트 데이터로 파헤쳐볼 수 있다는 점이 인상적이었습니다.
2. 띵동, 오늘의 사연이 왔어요! 편지 속 문장의 단어를 시각화한 사례
누구나 갖고 있는 고민, 여러분은 어떻게 고민을 나누시나요? 만약, 우리들의 고민을 모두 데이터로 기록하고, 시각화한다면 어떤 의미를 알 수 있을까요? 이번 사례는 The Pudding의 “30 Years of American Anxieties”라는 시각화 콘텐츠로 편지 속 사연의 단어를 시각화해 인사이트를 전달하는데요! 함께 살펴보도록 하겠습니다.
혹시 Dear Abby라는 칼럼을 알고 계신가요? Dear Abby는 미국에서 가장 오래 연재된 칼럼으로, 1956년부터 시작돼 현재까지 이어지고 있습니다. 독자들의 편지를 수기와 온라인으로 받아 관련된 조언을 칼럼으로 제공하고 있는데요. The Pudding은 독자들이 Dear Abby에게 보낸 편지 총 2만 개가 담긴 데이터셋을 이용해 시각화 콘텐츠를 만들었습니다.
수만 개의 편지에는 다양한 사연이 섞여 있을 수밖에 없을 텐데요! The Pudding은 총 2가지 분석 기준으로 편지를 분류해 인사이트를 발견하고자 했습니다. 첫 번째 분석 기준은 사연 중 가장 자주 등장하는 주제가 무엇인지를 파악한 것으로, 그 결과 편지를 3가지 유형으로 구분했습니다. ‘성 관련(sex-related)’, ‘LGBTQ 관련(LGBTQ-related)’, ‘종교 관련(religion-related)’이 이에 해당합니다. 3가지 중 현재까지도 미국 사회의 커다란 영향을 끼치고 있는 종교에 관한 사연을 살펴보도록 하겠습니다!
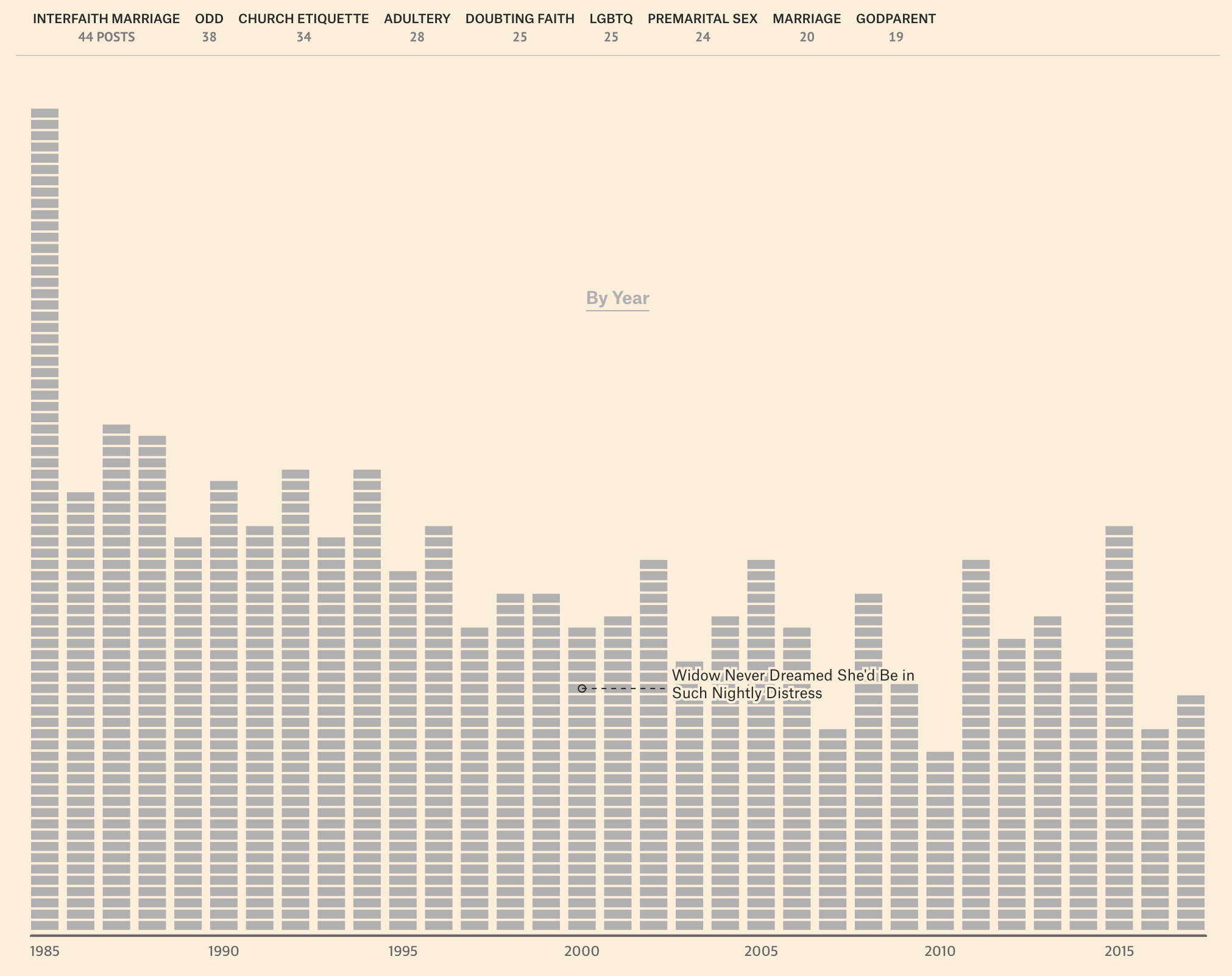
위 이미지는 종교와 관련된 고민 편지의 수를 연도별로 시각화해 나타낸 막대 차트입니다. 차트의 막대는 조각으로 나뉘어 표현되었는데요. 각 조각은 개별 편지를 의미하며 X축은 연도를, Y축은 종교 관련 편지의 빈도수를 나타냅니다. 이를 통해 연도별 종교 관련 고민 편지의 빈도수 변화를 살펴볼 수 있습니다.! 종교 관련해서는 1985년 가장 많은 편지 수를 기록한 이래로 2017년 소폭 줄어들었지만, 종교와 관련된 사연은 꾸준히 존재해왔음을 알 수 있습니다.
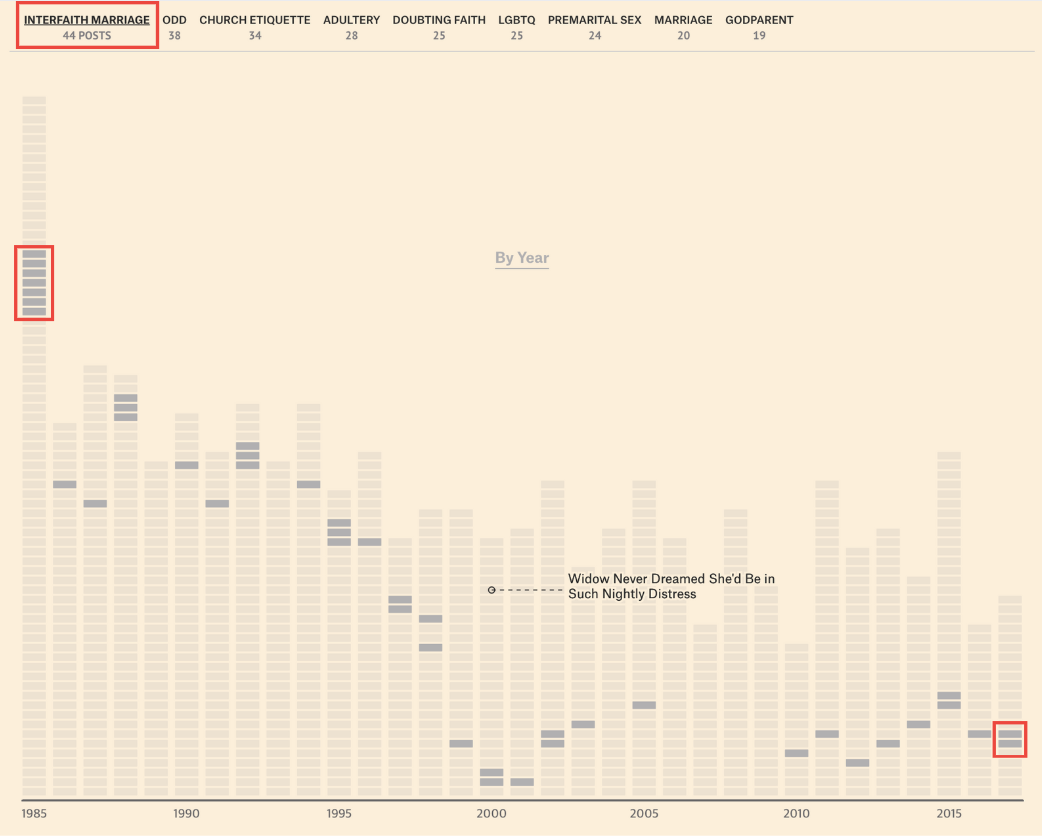
차트 가장 상단의 텍스트를 보면 종교의 세부적 고민 항목과 편지 수 또한 확인할 수 있는데요. 가장 자주 등장하는 종류는 ‘타 종교 간 결혼(interfaith marriage)’, ‘이상한(odd) 고민’, ‘교회 에티켓(church etiquette)’ 순으로 나타났습니다.
차트 위 세부 고민 항목을 마우스로 클릭하면 차트에서 해당 데이터만 하이라이팅되어 연도별 등장 빈도를 직관적으로 확인할 수 있는데요. 가장 많이 누적된 항목인 ‘타 종교 간 결혼(interfaith marriage)’은 1985년에 비교적 많이 등장했지만, 시간이 지남에 따라 등장 빈도가 점차 감소한 걸 볼 수 있습니다. 막대 차트의 조각을 하나하나 세어보면, 1985년에 ‘타 종교 간 결혼(interfaith marriage)’ 관련 사연은 7건이었지만, 가장 최근 연도인 2017년에는 단 2건에 불과했습니다. 종교는 여전히 자주 등장하는 고민 주제이지만, 세부적으로 나누어 보면 시간의 흐름에 따른 변화를 파악할 수 있습니다.

The Pudding은 두 번째 분석 기준으로 편지의 고민 대상이 누구인지로 두고 남편, 아내, 아들, 딸, 친구, 상사를 중심으로 고민 주제를 파악했는데요! 위 이미지는 그중 모두가 공감할 수 있는 친구와 관련된 주제를 비중으로 나타낸 유닛 차트입니다. 유닛 차트의 블록은 개별 편지를 나타내며 주제별 편지 수를 비교할 수 있습니다. 왼쪽의 유닛 차트를 보면 친구 관련 고민 주제 중 ‘무례함(Rudeness)’과 ‘에티켓(Etiquette)’이 각각 16개와 11개로 가장 많다는 걸 볼 수 있습니다. 다른 대상에 대한 고민 주제는 어떻게 다를까요?

위 이미지는 상사에 대한 고민을 주제별로 나눈 유닛 차트입니다. 상사에 관한 사연은 주로 ‘부적절한 행동(Inappropriate)’과 ‘로맨스(Romance)’ 주제가 가장 많다는 것을 알 수 있습니다. 이를 통해 고민의 대상에 따라 나뉘는 주제 또한 다양하다는 것을 파악할 수 있습니다.
두 번째 사례는 2만 개의 고민 편지에 담긴 사연을 데이터화하고, 기준별로 편지를 분류하며 세부적으로 분석한 콘텐츠였는데요. 시기에 따라 사람들의 고민 주제가 달라지고, 고민 대상에 따라 주제 또한 어떻게 달라지는지를 알 수 있다는 것이 인상적이었습니다.
3. 좋아요와 싫어요, 당신의 선택은? 데이팅 앱에 언급된 단어 호감도를 시각화한 사례
여러분은 보통 연인과 어떤 주제로 대화를 하나요? 혹시 나이가 들면서 대화의 주제가 달라지고 있음을 경험하신 적이 있을까요? 마지막으로 살펴볼 콘텐츠 사례는 특정 단어에 관한 사람들의 호감도 데이터를 활용한 The Pudding의 “10 Things Everyone Hates About You”입니다.

콘텐츠에 활용된 데이터는 미국의 데이팅 앱 ‘헤이터(Hater)’를 출처로 합니다. ‘헤이터(Hater)’에서는 사용자가 특정 단어를 보고 ‘좋아요’ 혹은 ‘싫어요’를 누르면, 해당 단어에 동일한 호감도를 가진 사람들 서로를 매칭시켜주는 기능이 있는데요.
The Pudding은 ‘헤이터(Hater)’에 제시된 단어들의 누적된 ‘좋아요’와 ‘싫어요’ 클릭 수 데이터를 2가지 방식으로 분석했는데요. 첫 번째 방식은 모든 단어를 특정 주제 아래로 분류한 뒤, 각 단어의 호감도를 연령대별로 시각화한 것입니다. 어떤 흥미로운 인사이트를 발견할 수 있는지 함께 차트를 해석해볼까요?
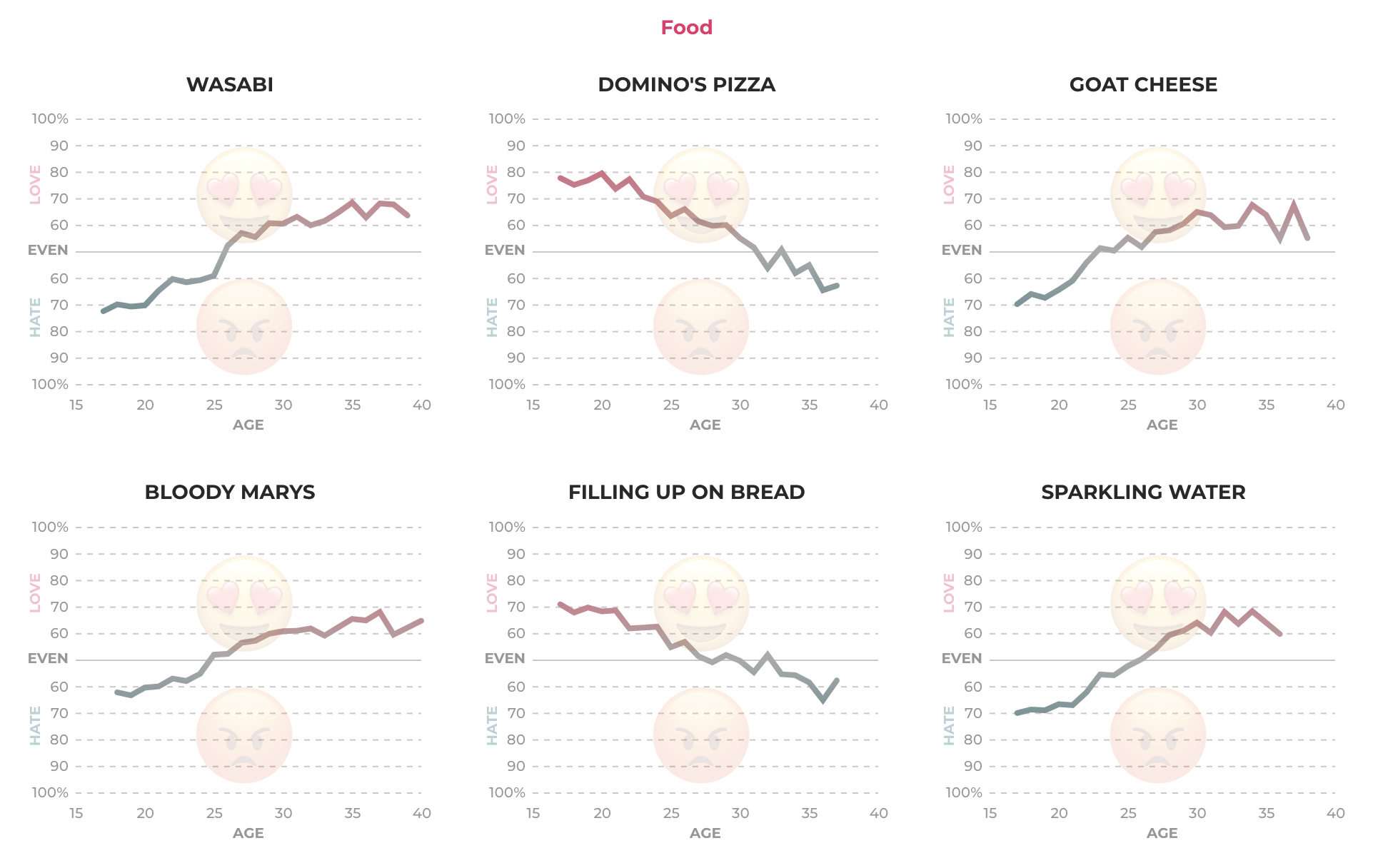
위 이미지는 분류된 주제 중 음식과 관련된 단어들의 연령대별 호감도 변화를 보여주는 라인 차트입니다. X축은 연령을 나타내며, Y축은 ‘좋아요’ 혹은 ‘싫어요’ 클릭 수의 비중을 표현했습니다. Y축의 중간 지점은 ‘좋아요’와 ‘싫어요’의 비중이 5:5로 같다는 것을 의미하고, 위쪽은 ‘싫어요’보다 ‘좋아요’ 비중이 높았을 때의 ‘좋아요’ 비중, 아랫쪽은 ‘좋아요’보다 ‘싫어요’의 비중이 더 높았을 때의 ‘싫어요’ 비중을 의미합니다. 다시 말해, 선의 각 지점이 올라갈수록 해당 단어에 대한 더 큰 호감을 의미하고, 내려갈수록 더 큰 비호감을 뜻합니다. 위 이미지의 6개의 음식 단어별 라인 차트는 격자 형태로 나열되어 있는데요, 이런 시각화 방식을 스몰 멀티플즈라고 합니다. 한눈에 여러 단어의 데이터 추세 차이를 파악할 수 있습니다.
가장 왼쪽 위의 첫 번째 단어인 ‘와사비(Wasabi)’ 라인 차트를 보면 연령대가 높아질수록 호감도 라인도 상승하는 것을 알 수 있는데요. 와사비에 대한 호감도가 25세까지는 비호감에 머물다가 이후 급격히 상승하며 금세 호감으로 바뀐 것을 볼 수 있습니다. 바로 옆의 ‘도미노 피자(Domino’s Pizza)’는 어떨까요? ‘와사비(Wasabi)’와 반대로 ‘도미노 피자(Domino’s Pizza)’에 대한 호감도는 나이가 들수록 급격히 하락하는데요. 20대 중반까지는 ‘도미노 피자(Domino’s Pizza)’에 대한 호감도가 높다가 30대를 들어서고 비호감으로 바뀌었습니다. 이로써 연령대별로 단어에 대한 호감도가 유의미하게 변화한다는 것을 알 수 있습니다.
하나의 단어별 ‘좋아요’,’ 싫어요’ 클릭 수 비중을 연령별로 살펴보면서, 특정 단어에 대한 호감도 변화를 쉽게 파악할 수 있었는데요! 전체 연령을 기준으로 호감도를 종합해보면 무엇을 알 수 있을까요? The Pudding은 두 번째 분석 방식으로 단어별 ‘좋아요’, ‘싫어요’ 클릭 수의 비중을 비교하여, ‘좋아요’가 압도적으로 높은 단어, ‘싫어요’가 압도적으로 높은 단어, ‘좋아요’와 ‘싫어요’ 클릭 수가 비슷한 단어로 구분했습니다. 이 경우, 누구나 호감, 비호감을 가진 단어가 무엇인지 알 수 있을 뿐만 아니라, 호감과 비호감 그 사이에서 애매한 단어가 무엇이 있는지 알 수 있는데요. 아래의 시각화로 함께 확인해보시죠!
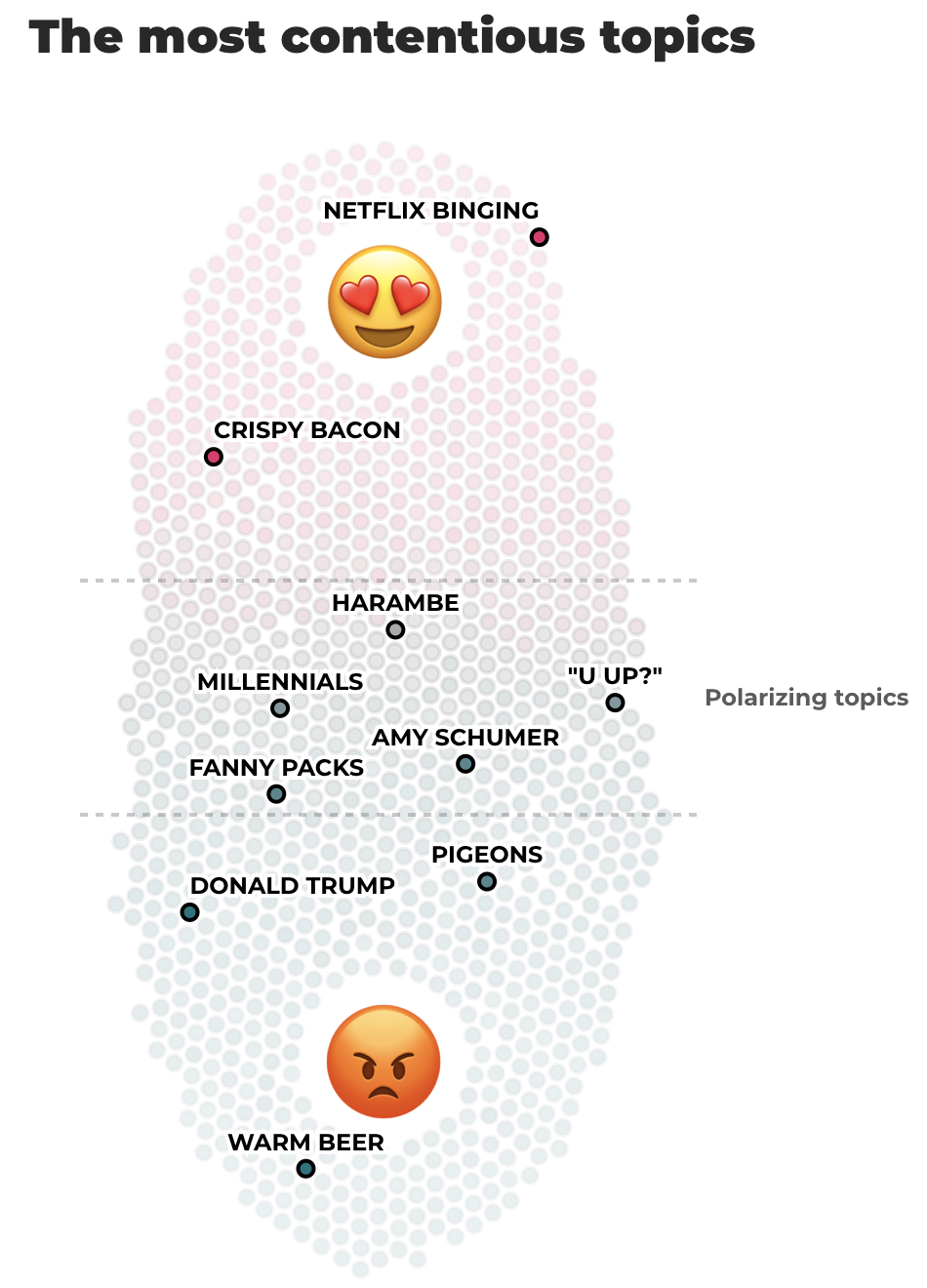
위 시각화는 단어별 호감도를 분포로 나타낸 벌집 플롯 (beeswarm plot)입니다. 벌집 플롯은 개별 단어가 서로 겹치지 않고 동그랗게 따로 놓여 있어 마치 벌집을 연상케 하는데요. 단어의 ‘좋아요’와 ‘싫어요’ 클릭 수에 따라 압도적인 호감은 상단에 핑크색으로, 비호감은 하단에 파란색으로 나뉘어져 있습니다. 그리고 ‘좋아요’와 ‘싫어요’ 클릭 수가 대등해 호감도가 애매한 단어는 중앙에 보라색으로 나타났습니다. 벌집 플롯으로 3가지 종류의 호감도 안에 각각 어떤 단어들이 포함되어 있는지, 하나씩 살펴볼까요?
우선 확신의 호감을 느낀 단어를 보도록 하겠습니다! 플롯의 상단을 확인해 보니 ‘바삭바삭한 베이컨(Crispy Bacon)’과 ‘하루 종일 넷플릭스 시청하기(Netflix Binging)’가 있습니다. 그럼 반대로 확신의 비호감인 단어는 무엇일까요? 플롯의 하단을 보면 ‘뜨뜻미지근한 맥주(Warm Beer)’, ‘비둘기(Pigeons)’, 그리고 ‘도널드 트럼프(Donald Trump)’가 있습니다. 이제 플롯의 중앙에 위치한 의견이 분분한 단어들을 살펴보겠습니다. 이 중 ‘밀레니얼(Millennials)’, ‘올리브(Olives)’, 그리고 ‘인공지능(Artificial Intelligence)’ 등 다양한 주제의 단어들이 보입니다! 이로서 단순히 이분법적으로 ‘호감’과 ‘비호감’이 아닌, 선호도가 불분명한 단어들이 존재한다는 것을 알 수 있습니다.
이번 사례에서는 사람들이 특정 단어에 대해 가지고 있는 호감도를 데이터화해서 시각화했는데요. 특정 주제 아래 여러 단어 데이터를 연령대별로 묶었을 때 단어에 대한 호감도가 바뀌는 걸 확인하는 유의미한 시도였습니다. 이에 그치지 않고 단어의 ‘호감’과 ‘비호감’이 아닌, 애매한 호감도를 가진 단어들을 추려내어 시각화하기도 했는데요. 많은 사용자가 쉽게 소통하는 앱에서 언급되는 단어별 호감도를 시각화 함으로써, 단순히 대화를 나누고 있다는 것에서 나아가, 어떤 주제로, 어떤 감정적 반응을 하고 있는지 알 수 있다는 점이 의미 있는 사례인 것 같습니다!
에디터의 한마디
지금까지 다양한 단어 시각화 사례를 통해 텍스트 데이터를 어떻게 활용할 수 있는지 알아보았는데요! 우리가 일상생활에서 쉽게 접하는 단어를 시각화하여 사람들에 대한 흥미로운 인사이트를 빠르게 얻을 수 있었습니다. 철학자 하이데거의 말을 되새기며 시각화로 확인하니, 실제로 언어가 우리 존재를 드러내는 지표처럼 보이지 않으신가요? 여러분의 생각은 어떠신가요?
가장 중요한 점은 방대한 양의 단어를 데이터로 만들어 시각화함으로써 언어에 숨겨진 다양한 이면을 발견할 수 있다는 것입니다. 데이터 시각화는 단순히 성과 지표를 보여주는 것이 아니라, 보다 부드럽고 섬세한 인간의 면모를 파헤치는 데 사용될 수도 있다는 점도 덧붙이고 싶은데요. 오늘의 글을 통해 다양한 단어 시각화 사례를 접하면서 데이터 시각화에 대한 이해가 더욱 확장되었길 바랍니다! 🙂
<참고 자료>
- 뉴스젤리, “‘아이콘’을 활용한 데이터 시각화, 유닛 차트를 아시나요?”, 2025-02-12
- 뉴스젤리, “2024 파리 올림픽, 데이터 시각화로 본다면?”, 2024-08-29
- “Basic beeswarm plot with R”, R graph gallery
- Rachel Nuwer, “Dear Abby, America’s Favorite Advice Columnist, Dies at 94”, Smithsonian Magazine, 2013-01-17
Editor. 기획팀 은젤리
