사례를 통해 알아보는 시계열 데이터 시각화 유형 모음
데이터를 분석하다 보면 시계열 데이터를 자주 접하게 되는데요. 날짜나 시간 정보를 포함한 시계열 데이터는 시간에 따른 데이터의 변화를 파악하는 데 매우 유용하기 때문입니다. 특히 시계열 데이터가 담고 있는 인사이트를 발견하는 과정에서 시각화는 중요한 역할을 하는데요! 시계열 데이터를 차트로 표현할 때 가장 먼저 떠오르는 시각화 유형은 무엇일까요? 아마도 대표적인 라인 차트가 생각나실 겁니다.
라인 차트는 시점별로 데이터의 절대치를 비교하며 추이를 파악하는 데 사용됩니다. 선의 높낮이로 데이터의 크기를 비교하는 것이죠. 그렇다면, 시계열 데이터를 분석할 때 활용할 수 있는 차트는 라인 차트뿐일까요? 다른 시각화 유형은 없을까요? 그렇지 않습니다! 라인 차트와 동일하게 X축을 시계열 데이터 기준으로 사용하지만, 목적에 따라 조금씩 다른 형태의 시각화 유형들이 존재하는데요! 이를 제대로 이해하고 활용한다면 보다 풍부한 데이터 인사이트 도출을 할 수 있을 뿐만 아니라, 시각화 차트를 보는 사람들을 효과적으로 설득할 수도 있습니다. 따라서 오늘은 시계열 차트의 기본인 라인 차트에서 시작해, 다소 생소하지만 활용 목적에 따라 시도해볼만한 시계열 데이터의 시각화 유형 다섯가지를 소개해드리도록 하겠습니다!
1. 라인 차트 (line chart): 가장 기본적인 시계열 데이터 패턴을 보고싶을 때
첫 번째로 소개할 유형은 가장 기본적인 시각화 유형 중 하나로, 시간에 따른 데이터 변화를 선으로 보여주는 라인 차트(line chart)입니다. 라인 차트는 시계열 데이터를 기준으로 각 시점의 절대치를 점으로 찍고 선으로 연결한 형태인데요! 연결된 선의 높낮이 변화를 바탕으로 절대치의 흐름을 파악할 수 있습니다.
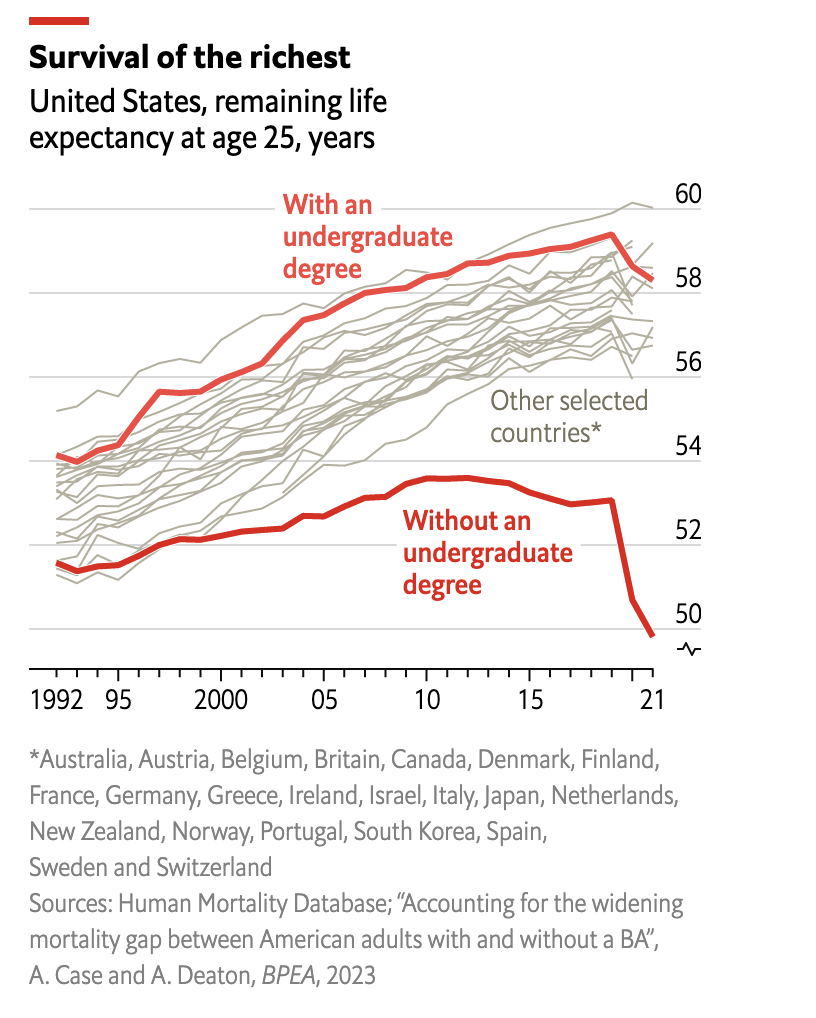
사례를 한 가지 살펴볼까요? 위 사례는 학부 졸업 여부에 따른 25세 청년의 기대수명을 연도별로 나타낸 라인 차트입니다. 라인 차트의 선은 국가별 학부 졸업 여부에 따라서 구분되었습니다. X축은 1992년부터 2021년까지의 연도를 나타내며, Y축은 기대수명을 나타내는데요. 선의 위치가 높을수록 남은 수명이 더 길고, 낮을수록 더 짧음을 의미합니다. 여기서 유의할 점은 Y축의 시작점이 0이 아닌 약 50에서 시작한다는 것인데요! 일반적으로 차트의 Y축은 0에서 시작해야 의미가 왜곡되지 않는다고 하지만, 온도와 기대수명처럼 데이터 크기의 변화가 미미한 주제에 한해서 Y축을 0이 아닌 값에서 시작하기도 합니다.
차트를 보면 빨간색 선과 회색 선으로 구분됨을 알 수 있는데요! 미국의 사례를 강조하기 위해 미국 데이터를 빨간색으로, 나머지 국가는 모두 회색으로 표시했습니다. 빨간색 선 두 개를 보면, 학부 졸업자는 상단 선, 학부 미졸업자는 하단 선에 위치함을 차트에 표시된 텍스트로 확인할 수 있습니다.
1992년부터 2021년까지 미국의 선(빨간색) 추이를 살펴보면, 학부 졸업자(상단)와 미졸업자(하단)의 기대수명 격차가 점차 벌어지는 추세를 확인할 수 있습니다! 차트 왼쪽을 보면, 가장 과거 시점인 1992년에 학부 졸업자(상단)의 기대수명은 약 54년이며 학부 미졸업자(하단)의 기대수명은 약 52년으로 2년 차이가 나는데요. 이는 25세의 학부 졸업자가 79세까지, 미졸업자가 77세까지 살 것으로 해석할 수 있습니다. 가장 최근 시점인 2021년을 차트 오른쪽에서 보면, 학부 졸업자(상단)의 기대수명은 58년, 미졸업자(하단)의 기대수명은 50년으로 나타났는데요. 이는 2021년을 기준으로, 25세 학부 졸업자는 58년 이후인 83세까지 살 것이며, 25세 학부 미졸업자는 50년 이후인 75세까지 살 것이라는 의미입니다. 이들은 무려 8년 차이로 1992년 당시 격차보다 4배 증가했습니다!
위 사례로 알 수 있듯이 라인 차트를 활용하면 시간에 따른 수치 데이터의 변화를 비교하며 추이를 한 눈에 파악할 수 있습니다. 라인 차트는 짧은 기간의 데이터를 단순 비교하는 것보다, 장기간의 데이터를 비교하며 데이터 인사이트를 도출하기에 더욱 적합합니다. 한편, 라인 차트를 만들 때 유의해야 할 점은 하나의 차트에 너무 많은 선이 있지 않도록 해야 한다는 것인데요! 너무 많은 선이 있으면 항목별 데이터를 비교하기 어렵기 때문에, 가급적 다섯 개 이하의 선으로 항목을 구분하거나 색상으로 강조하는 것이 좋습니다.
2. 100% 누적 영역 차트 (100% stacked area chart): 데이터의 비중 흐름을 보고싶을 때
두 번째 시각화 유형은 영역 차트의 종류 중 하나로, 비중의 변화를 효과적으로 보여주는 100% 누적 영역 차트(100% stacked area chart)입니다. 이 유형은 겉보기에는 여러 영역 차트를 합쳐 누적 합계를 나타낸 누적 영역 차트와 유사해보이는데요! 하지만 두 차트에는 중요한 차이가 있습니다.
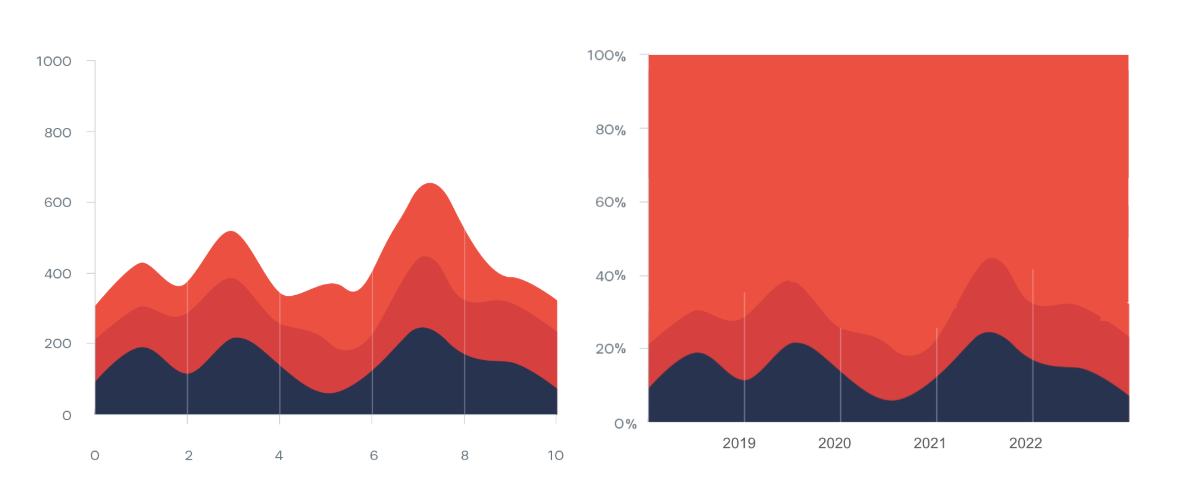
누적 영역 차트는 Y축 범위를 절대치로 유지하며 항목별 선 하단 영역에 색을 채워 단순히 쌓는 방식인데요. 이와 달리 100% 누적 영역 차트에서는 Y축 범위의 끝을 100%로 고정하고, 그 안에서 각 항목이 차지하는 비중을 색으로 채우며 항목별 비중 추이를 비교할 수 있도록 합니다.
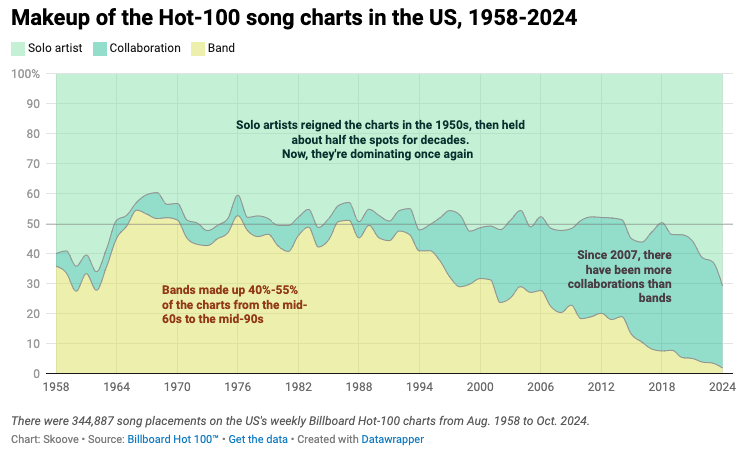
위 사례는 연도별로 음악 차트 100위 안에 든 횟수를 아티스트 유형의 비중으로 나타낸 100% 누적 영역 차트입니다. X축은 1958년부터 2024년까지의 연도이며, Y축은 전체의 100%를 나타냅니다. 차트는 세 가지 아티스트 유형인 솔로 아티스트, 콜라보레이션, 그리고 밴드가 차트 상위권을 차지한 비중을 색상으로 구분했는데요! 옅은 초록색은 솔로 아티스트, 짙은 초록색은 콜라보레이션, 짙은 노란색은 밴드를 뜻합니다. 각 항목이 차트에서 차지하는 영역이 클수록 해당 아티스트 유형이 차트 상위권에서 더 큰 비중을 차지했음을 의미합니다.
차트를 자세히 읽어볼까요? 1958년부터 1994년대까지는 솔로 아티스트(옅은 초록색)와 밴드(짙은 노란색)가 음악 차트 상위권의 대부분을 차지했습니다. 그러나 이 흐름은 1994년부터 변화하기 시작하는데요! 밴드(짙은 노란색)의 상위권 차지 비중이 점차 감소하는 동시에 중앙에 위치한 콜라보레이션(짙은 초록색)의 비중이 점점 증가하는 추세를 보입니다! 가장 최근 조사연도인 2024년도 데이터는 차트 가장 오른쪽 부분에서 확인할 수 있는데요. 2024년에 솔로 아티스트(옅은 초록색)의 음악 차트 상위권 차지 비중이 약 70%로 강세를 유지하는 반면, 콜라보레이션(짙은 초록색)이 음악 차트 상위권에서 25%를 차지하며, 밴드(짙은 노란색)의 비중 4%를 압도하고 새로운 트렌드로 부상했습니다.
이처럼 100% 누적 영역 차트는 데이터 항목별 영역 크기를 통해 시간에 따른 비중 변화를 한눈에 파악할 수 있는 강력한 시각화 유형입니다. 다만, 100% 누적 영역 차트도 라인 차트처럼 항목 수가 많아질수록 해석이 어려워진다는 한계가 있는데요. 또 X축에 가까운 항목이나 가장 상단의 항목은 기준선을 바탕으로 비교적 쉽게 해당 영역의 비중 추이를 읽을 수 있지만, 중앙에 위치한 항목은 비중 변화를 명확히 파악하기 어렵다는 단점도 있습니다. 이런 한계를 극복할 수 있는 다른 시계열 시각화 차트가 있을까요?
3. 스트림 차트 (stream chart): 여러 항목의 영역 흐름을 개별적으로 보고싶을 때
세 번째 시각화 유형은 여러 항목의 영역 흐름을 보여주는 스트림 차트(stream chart)입니다! 시각화 차트의 형태를 보았을 때, 이번 시각화 유형 또한 누적 영역 차트와 유사하게 보이는데요! 역시 몇 가지 구별되는 차별점이 있습니다.
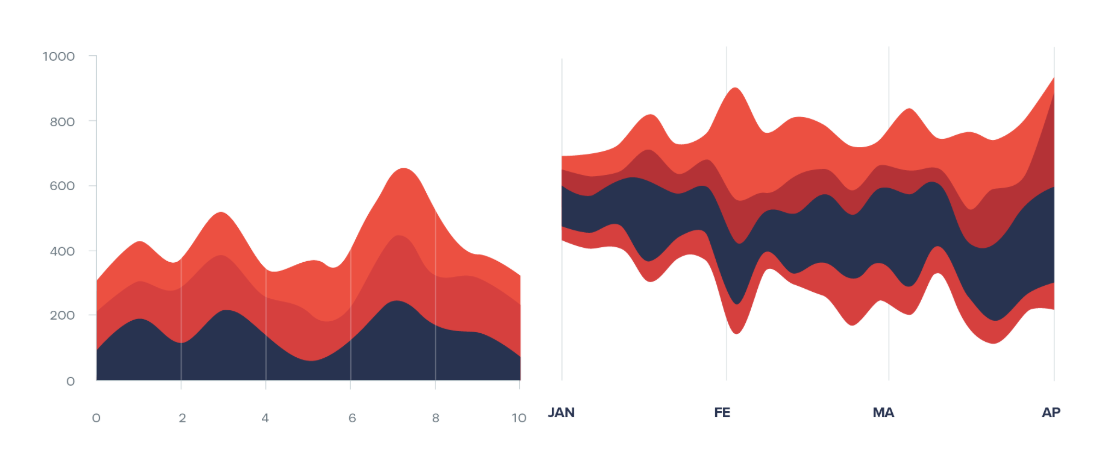
누적 영역 차트는 하단 기준선에서부터 항목별 영역을 위로 쌓아가는 구조이기 때문에, 가장 하단에 위치한 항목의 영역 크기를 비교하기 가장 쉽습니다. 반면, 그 위에 쌓인 항목은 영역 크기를 기준선 없이 파악해야 하므로, 크기 변화를 파악하기 쉽지 않은데요.
반면, 스트림 차트는 Y축 중앙을 기준으로 두며 항목별 영역을 위와 아래로 쌓기 때문에 항목이 여러개라도 이들의 개별적인 영역 흐름을 파악할 수 있습니다. 스트림 차트의 주요 특징은 Y축에 구체적 수치를 표기하지 않는다는 점인데요! 시간에 따른 추세와 패턴의 변화를 발견하는 데 있어, 구체적 수치보다 색으로 구분된 항목별 영역의 흐름을 보여주는데 중점을 두기 때문입니다.
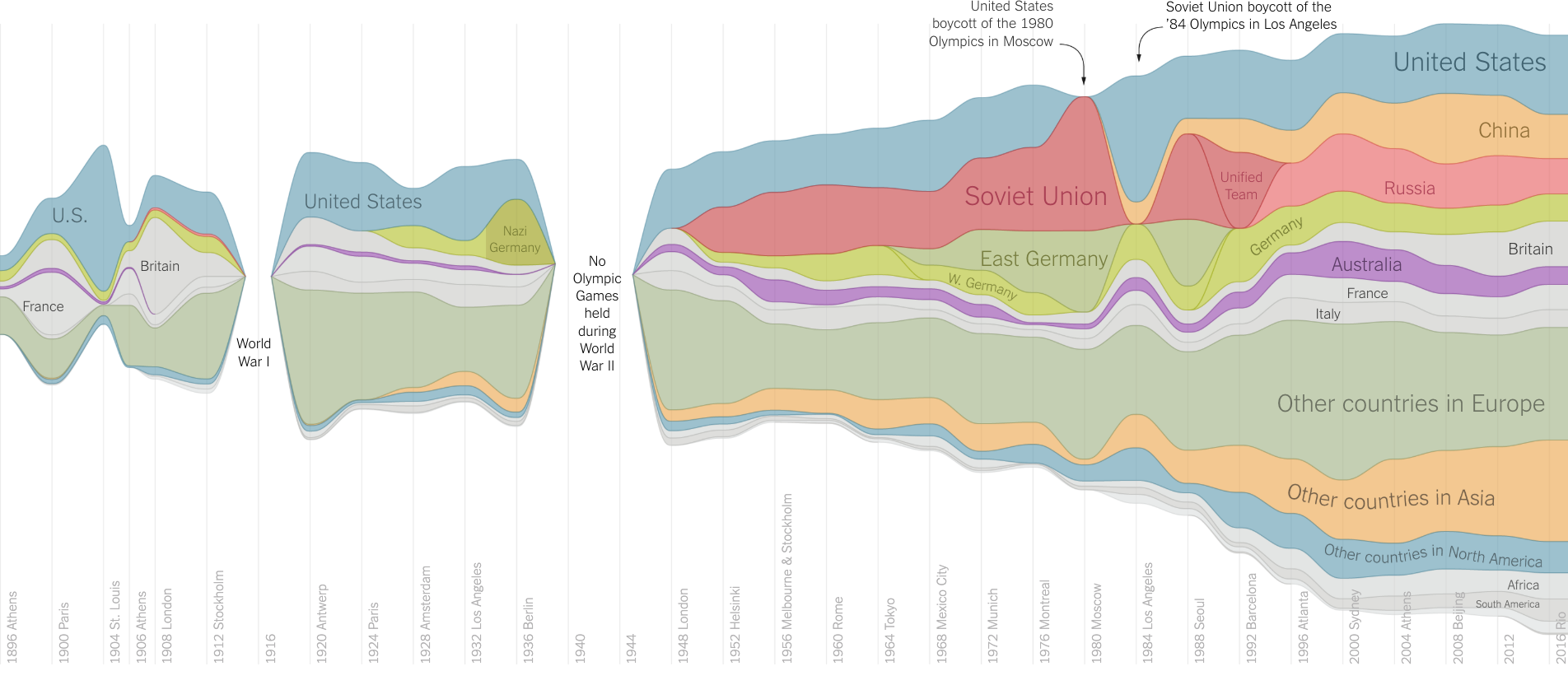
다소 생소하게 느껴지는 스트림 차트도 사례를 통해 이해를 더해보도록 하겠습니다. 위 사례는 시간에 따른 국가별 올림픽 금메달 수의 변화를 나타낸 스트림 차트입니다. X축은 1896년 아테네 올림픽부터 2016년 리우 올림픽까지를 나타내며, Y축은 금메달 수를 기반으로 항목의 영역 크기만 보여주고 있습니다.
차트에서 국가는 색상으로 구분됩니다. 모든 국가를 개별 색상으로 지정하기 한계가 있어 주요 국가를 제외하고 나머지는 대륙별로 묶어서 표현했는데요! 예를 들어, 짙은 파란색은 미국, 짙은 빨간색은 러시아로 표기한 반면, 짙은 초록색은 개별적으로 분류되지 않은 나머지 유럽 국가로 지정했습니다. 색상별 면적이 클수록 해당 국가가 금메달을 많이 딴 것을 의미하는데요! 가로 면적이 넓으면 더 오랜 기간 올림픽에서 금메달을 딴 국가라는 것을 알 수 있습니다.
조금 더 자세한 인사이트를 찾아볼까요? 올림픽의 초기와 후기의 금메달 보유국 수를 비교하면 차트의 핵심 메시지를 바로 파악할 수 있는데요. 차트 가장 왼쪽을 보면 초기 아테네 올림픽(1896년)에서 금메달을 딴 국가는 프랑스와 미국을 포함해서 약 10여개국임을 알 수 있습니다. 반대로 차트 가장 오른쪽은 리우 올림픽(2016년)으로 초기 아테네 올림픽과 비교했을때 훨씬 많은 국가가 금메달을 딴 것을 색의 가짓수로 바로 확인할 수 있는데요! 호주와 유럽, 아시아 등을 포함해 원문 기사에서는 무려 87개국으로 언급되며, 시간이 갈수록 더 많은 국가가 올림픽에서 승리를 거머쥔 것을 알 수 있습니다.
사례와 같이 차트에 표현할 항목이 87개로 굉장히 많으면 이들을 개별적으로 표현하기 쉽지 않은데요! 기존 누적 영역 차트처럼 차트의 하단 기준선을 고정시키고 한정된 영역에 항목별 영역을 쌓게 된다면, 각 항목의 영역 흐름을 보기 어려워집니다. 그러나 스트림 차트는 Y축 중앙을 기준으로 항목별 영역을 제한 없이 나열하기 때문에, 더욱 손쉽게 개별 항목의 영역 흐름을 살펴볼 수 있습니다. 다만 Y축이 부재하기 때문에 각 시점에서 특정 항목의 정확한 수치를 확인하기 어렵다는 단점이 있는데요. 이를 보완하기 위해 각 항목의 어노테이션, 혹은 툴팁으로 데이터 정보를 표기하기도 합니다. 만약 항목이 많은 시계열 데이터에서 시간에 따른 영역의 흐름을 파악하려고 한다면, 스트림 차트를 활용해보시기를 추천합니다!
4. 범프 차트 (bump chart): 시점별 데이터의 순위 변동을 보고싶을 때
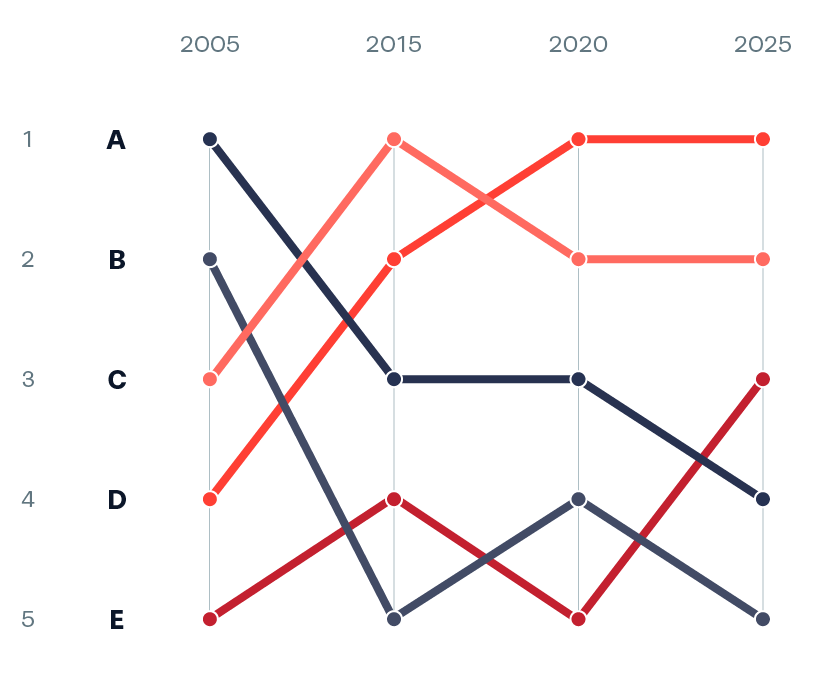
네 번째 차트 유형으로 시간 흐름에 따른 항목별 데이터의 순위 변동을 파악할 수 있는 범프 차트(bump chart)에 대해 알아보겠습니다. 범프 차트는 순위를 보는데 사용되기 때문에 랭킹 차트(ranking chart)라고도 불리는데요! 시계열 데이터를 활용해 각 시점별 항목의 순위를 점으로 표시하고 이를 선으로 연결하며, 선의 높낮이 변화로 순위 변동 추이를 파악할 수 있습니다.
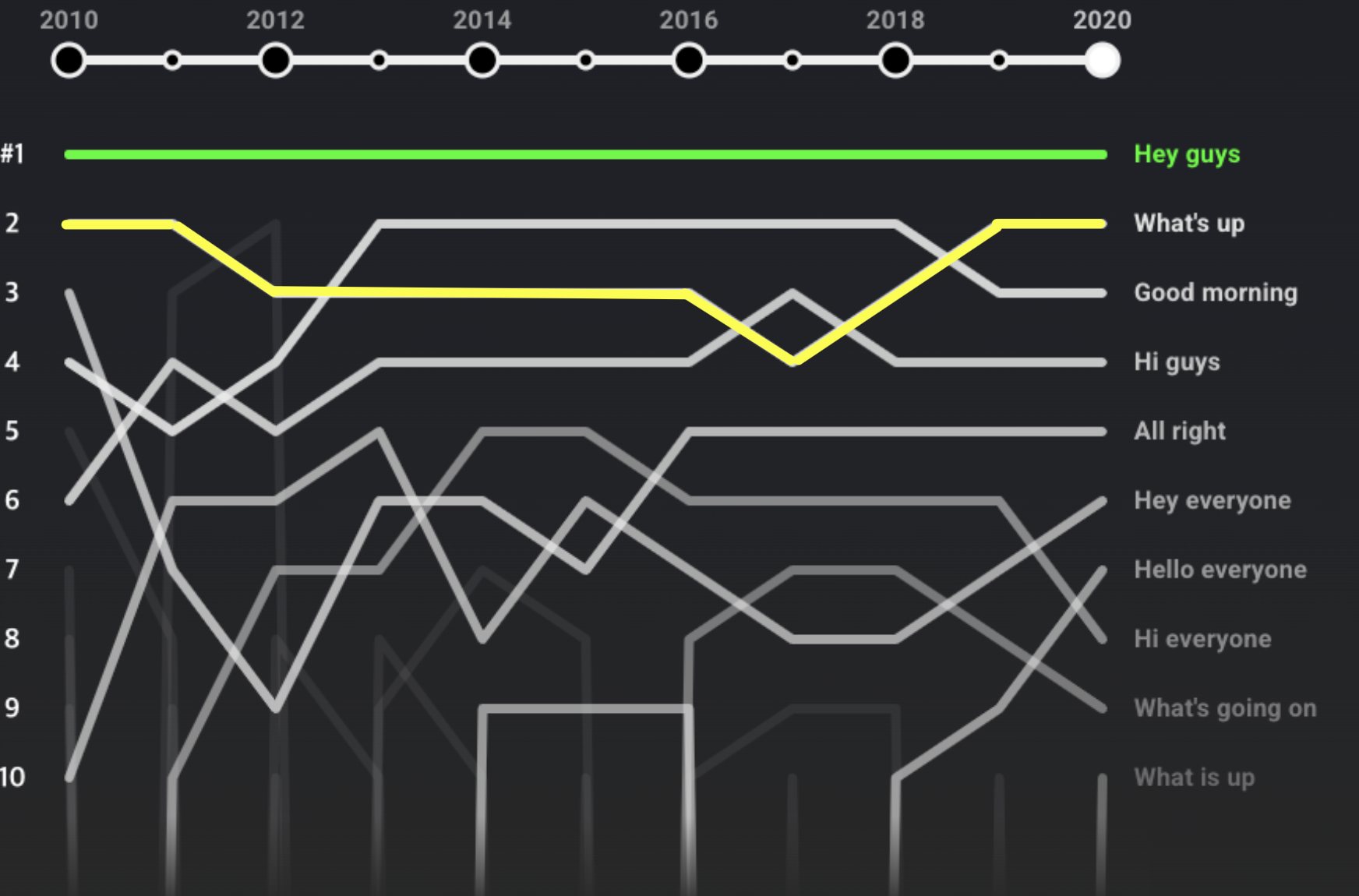
위 사례는 연도별 유튜브 인트로 멘트 선호도 변화를 나타낸 범프 차트입니다. X축은 2010년부터 2020년까지의 기간을, Y축은 특정 인트로 멘트가 활용된 빈도수를 기준으로 계산된 순위를 보여줍니다. Y축은 상단에서 1순위부터 하단의 10순위까지 내려오는 방식으로 구성되며, 각 멘트의 순위 변동을 선으로 연결해 직관적으로 볼 수 있습니다. 그럼 순위에 어떤 변동이 있었는지, 한 번 살펴볼까요?
차트의 왼쪽부터 오른쪽으로 시선을 옮겨보면, “Hey guys”(초록색)는 2010년부터 2020년까지 꾸준히 1순위를 유지하는 모습을 보여줬습니다! 반면 “What’s up”(노란색)은 2010년에 2위로 시작하여 이후 순위가 오르락내리락 하지만, 2020년에 최종적으로 2위를 유지하는 모습을 보였습니다.

여기서 든 한 가지 궁금증! 2020년 상위 10순위에 포함된 멘트는 모두 2010년에 있던 멘트들일까요? 2020년에 7위부터 10위를 기록한 멘트 선을 차트 오른쪽에서 왼쪽으로 역추적해보면, 이들은 모두 2010년에는 순위권 내에 없었다는 점을 확인할 수 있습니다! 해당 멘트들은 순서대로 “Hello everyone”(빨간색), “Hi everyone”(파란색), “What’s going on”(초록색), 그리고 “What is up”(노란색)입니다. 종합하면, 2010년 1위부터 6위의 멘트는 2020년에도 그대로 10위안에 들었지만, 7위부터 10위까지의 멘트는 새롭게 부상했음을 알 수 있습니다.
이처럼 범프 차트는 시간에 따라 변화하는 순위 데이터를 한눈에 파악해 직관적인 인사이트를 도출 할 수 있도록 도와주는데요! 아쉽게도 순위만을 표현하기 때문에 절대치나 비중 같은 정확한 데이터 수치를 알기 어렵다는 단점이 있습니다. 이 역시 툴팁을 통해 정확한 데이터 수치를 함께 제공한다면 데이터를 종합적으로 해석하는데 도움이 됩니다!
5. 누적 순서 영역 차트 (stacked ordered area chart): 시점별 데이터의 영역과 순위 변동을 동시에 보고싶을 때
앞서 살펴본 네 가지 시각화 유형은 시간 흐름에 따라 각각 절대치, 비중, 영역, 순위 변화를 표현하는데 효과적인데요! 혹시 영역과 순위의 변화를 한 번에 볼 수 있는 방법은 없을까요? 마지막으로 알아볼 시각화 유형은 시간에 따른 영역과 순위의 변화를 동시에 볼 수 있는 누적 순서 영역 차트(stacked ordered area chart)입니다!
누적 순서 영역 차트 또한 앞서 살펴보았던 누적 영역 차트와 비슷하게 생긴 것처럼 보입니다! 이 둘의 정확한 차이는 무엇일까요? 누적 영역 차트는 시간 흐름에 따른 항목별 영역 크기 변화를 비교하는데 효과적이라고 언급한 바 있는데요. 반면, 누적 순서 영역 차트는 시간 흐름에 따라 항목별 데이터의 크기를 영역의 크기로 표현하되 크기순으로 세로 기준 위치를 바꿔서 표현합니다. 항목별 데이터 크기가 크면 상단에 배치하고, 작으면 하단에 배치하는 방식인데요. 데이터 크기 변화에 따라 영역 순서가 바뀌는 시점의 모양이 리본을 연상케해 리본 차트(ribbon chart)라고도 불립니다!
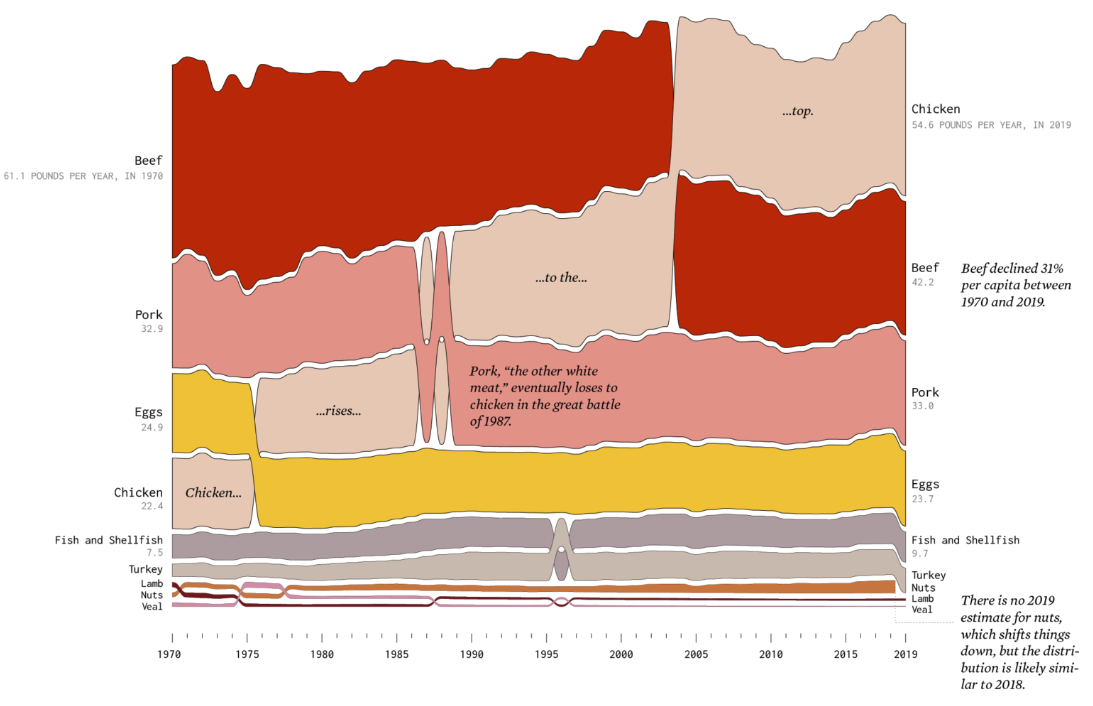
위 사례는 시간에 따라 변화하는 미국 내 단백질 식품 소비량을 보여주는 누적 순서 영역 차트입니다. X축은 1970년부터 2019년까지의 연도를, Y축은 종류별 단백질 식품 소비량을 나타냅니다. 데이터 값이 상대적으로 클수록 항목별 영역이 커지는데요. 가장 크기가 큰 항목은 1순위를 의미하는 차트 최상단에 배치됩니다. 이후 시간이 지나면서 순위가 변경될 경우, 항목의 배치 순서도 함께 재조정됩니다.
색으로 구분된 차트의 항목은 소고기, 돼지고기, 달걀 등의 식품 종류를 의미하는데요. 짙은 빨간색은 소고기, 옅은 빨간색은 돼지고기, 노란색은 달걀을 의미합니다. 2019년 기준으로 미국에서 가장 많이 소비한 단백질 식품은 무엇일까요? 차트에서 가장 오른쪽 상단에 위치한 베이지색 영역과 텍스트를 통해 닭고기임을 알 수 있습니다. 닭고기 소비는 1970년부터 최근까지 흥미로운 변화 추세를 보였는데요!
차트 가장 왼쪽 부분인 1970년을 보면, 닭고기(베이지색)는 전체 단백질 식품 소비량 중 4위로 바로 위에 달걀(노란색)이 3위를 차지했었는데요. 1975년경에는 닭고기(베이지색) 소비량이 증가하며 달걀을 제치고 3위로 올라섰습니다. 이후 닭고기(베이지색)은 1985년에서 1990년 사이에 2위였던 돼지고기(옅은 빨간색)와 치열한 순위 경쟁을 벌인 끝에 2위를 차지했습니다! 최종적으로 2004년에 1위를 유지하던 소고기(짙은 빨간색)를 제치고 단백질 소비량 1위에 등극했는데요! 시간 흐름에 따라 데이터의 크기 뿐만 아니라 순위가 한 단계씩 상승했음을 직관적으로 알 수 있습니다.
이처럼 누적 순서 영역 차트는 단순히 영역 데이터를 시각화하는 데서 나아가, 항목 간 순위 변화를 직관적으로 파악할 수 있는데 장점이 있는데요! 다만 누적 순서 영역 차트도 Y축 기준선이 고정되지 않은 구조로 인해, 각 항목의 정확한 수치를 바로 파악하기 어려운데요. 이러한 한계는 앞서 언급한 것과 같이 어노테이션이나 툴팁을 통해 추가 정보를 제공하는 방식으로 극복할 수 있습니다!
에디터의 한마디
지금까지 시계열 데이터를 효과적으로 활용할 수 있는 다섯 가지 시각화 유형을 살펴보았습니다. 사례의 차트를 직접 해석하면서, 데이터 인사이트를 도출해보니 보다 직관적으로 개별 시각화 유형이 가진 특징과 장점을 파악할 수 있었는데요! 오늘 다룬 다양한 시각화 유형들을 참고해서, 앞으로 시계열 데이터를 분석할 때 상황에 알맞은 시각화를 활용해보면 어떨까요?
단순히 절대치를 비교할 때는 1) 라인 차트를, 데이터 항목 간 비중을 비교할 때 2) 100% 누적 영역 차트를 사용하는 것이 좋습니다. 시계열 차트에서 너무 많은 항목이 표현되면 영역 흐름이 복잡해져서 데이터를 해석하기 어려운데요! 항목이 많은 경우에도 영역의 제한 없이 데이터를 비교하고 싶다면 3) 스트림 차트를 활용할 수 있습니다. 한편, 시점별 절대치보다 단순 순위 비교를 하고 싶다면, 4) 범프 차트를 활용할 수 있습니다. 나아가 항목별 영역뿐만 아니라 순위 변동을 동시에 보고 비교할 수 있는 시각화 유형으로 5) 누적 순서 영역 차트를 활용해보는 것도 좋은 방법이 될 것입니다.
한 가지 알아두면 좋을 점은, 오늘 소개된 시각화 유형들의 공통점이 모두 X축을 기준으로 시계열 데이터를 표현했다는 것인데요. 사실 시계열 데이터를 시각화하는 유형 중에는 X축에 시계열 데이터를 표현하는 방식이 아닌 형태도 있습니다! 낯설게 느껴질 수 있지만, 이런 유형의 시각화가 시계열 데이터를 다룰 수도 있으니, 관심을 갖고 살펴보시는 것도 추천드립니다.
(뉴스젤리는 이전에 시계열 데이터를 주제로 한 글을 발행한 적이 있는데요! 시계열 데이터를 시각화하여 인사이트를 도출한 사례와, 시각적 분석을 활용한 시계열 데이터의 실제 분석 과정을 다룬 글이 있습니다. 관심 있으시다면 해당 글도 읽어보시길 추천해드립니다!)
<참고 자료>
- 강원양, 임준원, 최현욱, 뉴스젤리, 2020, “데이터가 한눈에 보이는 시각화”
- 뉴스젤리, “아무도 알려주지 않는 ‘더 나은 시각화 만들기’ 노하우”, 2024-12-30
- 뉴스젤리, “위치 데이터 탐색의 길잡이, 지도 시각화 유형 모아 보기”, 2023-09-13
- 션 튜터의 엑셀 시각화 강의 교재, “02-03 영역 차트 (Area Chart)”, 2021-04-18
- Alex Kolokolov, “When Charts Looks Like Spaghetti, Try These Saucy Solutions”, 2023-09-07
- Andy Kirk, 2016, “Data Visualisation, A Handbook for Data Driven Design”
- Datawrapper, “How to create a bump chart”, 2025-02-25
- Flourish, “Streamgraphs: how to make them and what you need to know”, 2024-05-02
- Hamsini Sukumar, “Line charts: when to use them and when to avoid them”, Inforiver
- Hamsini Sukumar , “Line chart dos and don’ts: Creating an effective chart”, Inforiver
- Hamsini Sukumar, “Stacked area charts: When to use them and when to avoid them?”, Inforiver
- Mafe Callejón, “One dataset, ten visualizations”, Flourish, 2021-10-13
- The UN Refugee Agency, “Area Chart”
Editor. 기획팀 은젤리
